
Sélectionner une préparation dynamiquement lors de l'exécution selon le fichier source
Ce scénario s'applique à tous les produits Talend.
Pour plus de technologies supportées par Talend, consultez Composants Talend.
Le composant tDataprepRun vous permet de réutiliser une préparation existante créée dans Talend Data Preparation, directement dans un Job d'intégration de données, Spark Batch ou Spark Streaming. En d'autres termes, vous pouvez opérationnaliser le processus d'application d'une préparation à des fichiers d'entrée ayant le même modèle.
Par défaut, le composant tDataprepRun récupère les préparations en utilisant leurs identifiants techniques. Cependant, la fonctionnalité de sélection dynamique permet d’appeler une préparation grâce à son chemin dans Talend Data Preparation. En cochant la case Dynamic preparation selection et en utilisant quelques variables, il est alors possible de sélectionner dynamiquement une préparation au moment de l’exécution, en fonction des données ou métadonnées utilisées.
Si vous aviez voulu opérationnaliser des préparations dans un Job Talend en utilisant les propriétés de sélection de préparations classiques, il vous aurait fallu plusieurs Jobs : un pour chaque préparation à appliquer aux différents jeux de données. En récupérant la bonne préparation, en fonction du nom du fichier d'entrée, vous pourrez exécuter dynamiquement plusieurs préparations sur vos données source, en un seul Job.
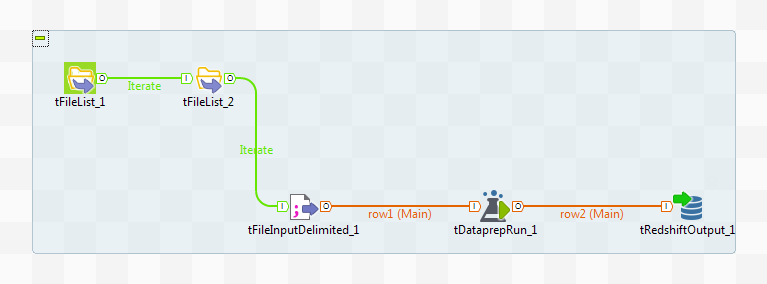
Le scénario suivant décrit un Job qui :
- lit le contenu d'un dossier contenant plusieurs jeux de données,
- crée un chemin dynamique vers vos fichiers CSV,
- récupère de manière dynamique les préparations en fonction du nom du fichier d'entrée et les applique sur vos données,
- envoie les données préparées dans une base de données Redshift.
Dans cet exemple, des jeux de données .csv contenant des données de deux de vos clients sont stockés localement dans un dossier nommé customers_files. Les jeux de données de chacun de vos clients possèdent une convention de nommage spécifique et sont stockés dans des sous-dossiers dédiés. Tous les jeux de données dans le dossier customers_files possèdent le même schéma, ou modèle de données.

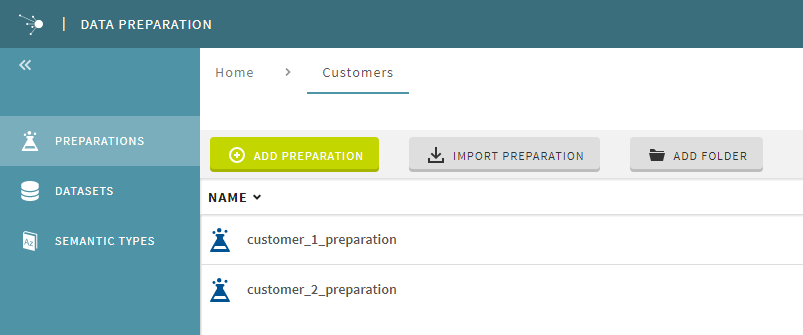
Un dossier customers, contenant deux préparations, a également été créé dans Talend Data Preparation. Ces deux préparations distinctes sont chacune destinées à la préparation des données de vos deux clients.
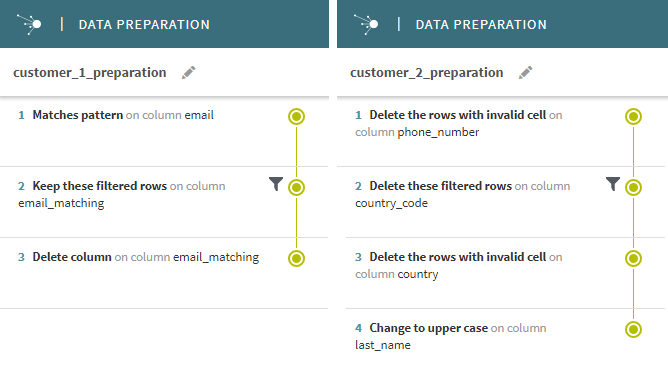
Le but de customer_1_preparation par exemple, est d'isoler un certain type d’adresses e-mail, alors que customer_2_preparation vise à nettoyer les valeurs invalides et mettre en forme les données. Dans cet exemple, les noms des préparations sont basés sur les noms des deux sous-dossiers customer_1 et customer_2, avec _preparation comme suffixe.
De la même manière que le schéma d'entrée qui est commun aux quatre jeux de données, toutes les données en sortie doivent avoir le même schéma. C'est pour cette raison que vous ne pouvez pas avoir d'un côté une préparation qui modifie le schéma en ajoutant des colonnes par exemple et pas de l'autre côté.
En suivant ce scénario, un unique Job vous permettra d'utiliser la préparation appropriée, selon que le jeu de données extrait du dossier local customers_files appartienne au client 1, ou au client 2.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !