
Exécuter le Job
Pourquoi et quand exécuter cette tâche
Vous pouvez exécuter ce Job.
Le composant tLogRow est utilisé pour afficher le résultat de l'exécution de ce Job.
Procédure
- Assurez-vous que votre programme de mise en flux de Twitter est toujours en cours d'exécution et continue à écrire les Tweets reçus dans le sujet donné.
- Appuyez sur F6 pour exécuter le Job.
Résultats
Laissez le Job s'exécuter un moment, puis, dans la console de la vue Run, vous pouvez voir que le Job liste les 5 hashtags les plus utilisés dans chaque batch de Tweets mentionnant Paris. Selon la configuration de la taille de chaque micro-batch et de la fenêtre Spark, chacun de ces batchs de Tweets contient les Tweets des 20 dernières secondes, reçus après chaque intervalle de 15 secondes.
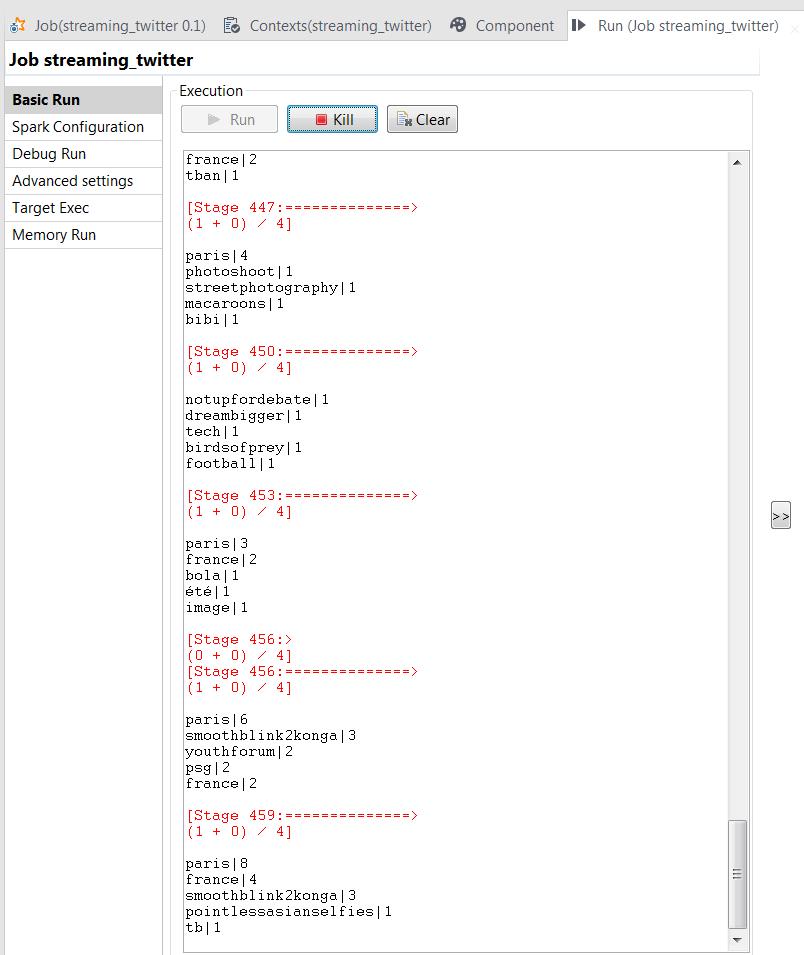
Notez que vous pouvez gérer le niveau d'informations relatives à l'exécution à afficher dans la console en cochant la case log4jLevel dans l'onglet Advanced settings et en sélectionnant le niveau d'informations que vous souhaitez afficher.
Pour plus d'informations concernant les niveaux de logs du log4j, consultez la documentation d'Apache : http://logging.apache.org/log4j/1.2/apidocs/org/apache/log4j/Level.html (en anglais).
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !