
Extraction de correspondances exactes à l'aide des règles d'Index
Ce composant est disponible dans Talend Data Management Platform, Talend Big Data Platform, Talend Real Time Big Data Platform, Talend Data Services Platform, Talend MDM Platform et Talend Data Fabric.
Pour plus de technologies supportées par Talend, consultez Composants Talend.
Dans ce scénario, vous allez standardiser des descriptions longues de produits clients en mettant en correspondance le flux d'entrée et les données contenues dans un index. Ce scénario vous explique comment utiliser les règles d'Index afin de mettre en jetons les données produit, puis de vérifier chaque jeton par rapport à un index, afin d'extraire les correspondances exactes.
Pour ce scénario, vous devez d'abord créer un index en utilisant un Job contenant un composant tSynonymOutput. Vous devez créer des index pour la marque, la finition, la couleur et l'unité de mesure des produits clients. Utilisez le composant tSynonymOutput afin de générer les index et de les alimenter par des entrées et des synonymes. La capture d'écran suivante illustre le Job :
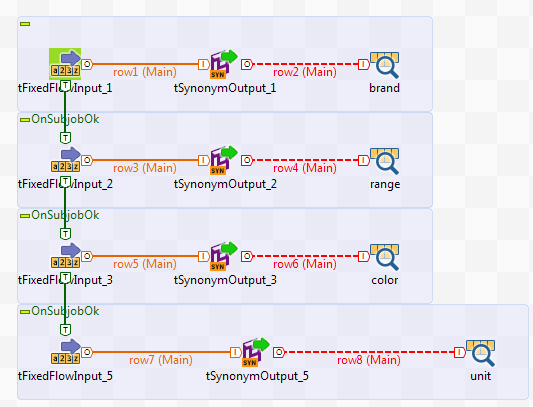
Ci-dessous se trouve un exemple d'index générés pour ce scénario :
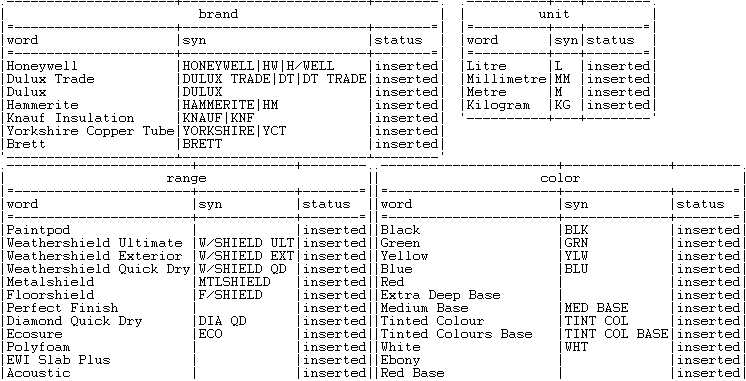
Chaque index généré a des chaînes de caractères (séquences de mots) dans une colonne et leurs synonymes correspondants dans une autre colonne. Ces chaînes de caractères sont utilisées en tant que données de référence par rapport auxquelles les données produits, générées par le tFixedFlowInput, vont être mises en correspondance. Pour plus d'informations concernant la création d'index, consultez tSynonymOutput.
Dans ce scénario, les index générés sont définis comme variables de contexte. Pour plus d'informations concernant les variables de contexte, consultez le Guide d'utilisation du Studio Talend.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !