
Configurer l'analyse de rapprochement
Procédure
-
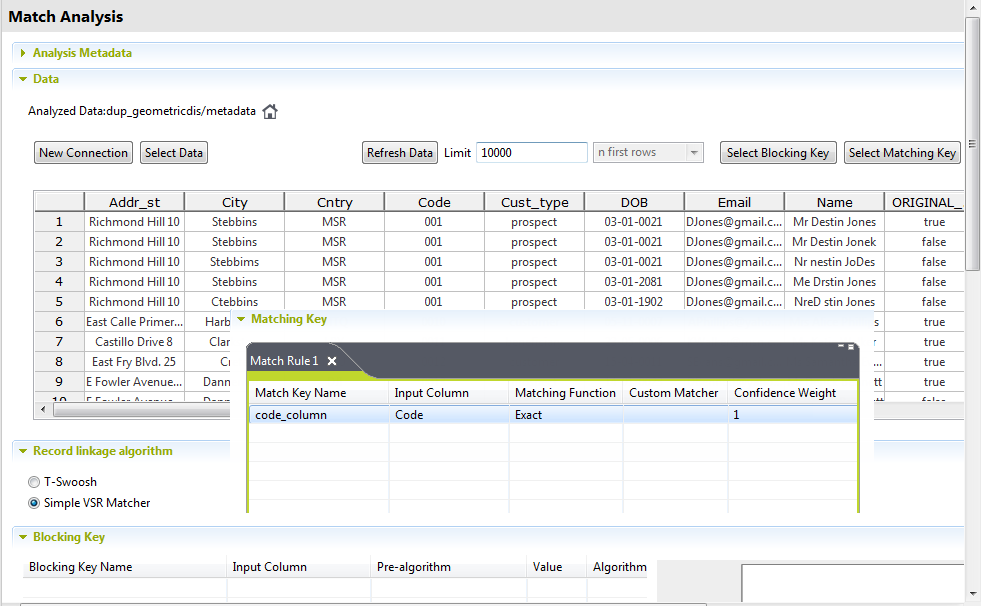
Dans la table Matching Key, définissez une clé de rapprochement sur la colonne Code, afin de regrouper les enregistrements selon leur identification, les enregistrements ayant le même code sont regroupés.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !