
Lire des données depuis HDFS à l'aide des métadonnées
Grâce au composant tHDFSInput, vous pouvez lire des données depuis HDFS.
Avant de commencer
- Ce tutoriel utilise un cluster Hadoop. Vous devez avoir un cluster Hadoop disponible.
- Vous devez également avoir une métadonnée HDFS configurée (consultez Créer une définition de métadonnée de cluster Hadoop et Importer une définition de métadonnée de cluster Hadoop).
- Vous devez avoir écrit des données dans HDFS (consultez Écrire des données depuis HDFS à l'aide des métadonnées).
Procédure
-
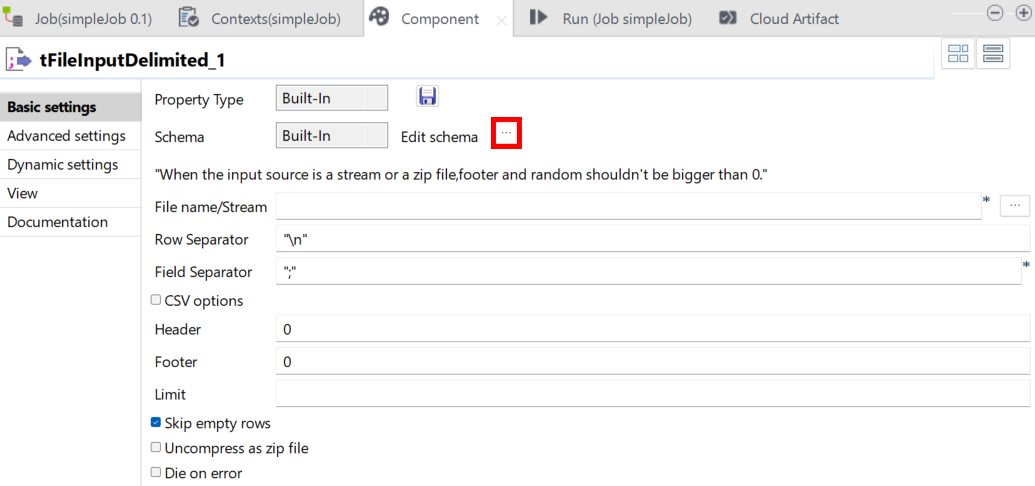
Cliquez sur le bouton [...] correspondant au champ Edit schema.
-
Cliquez-droit sur le tSortRow.
-
Cliquez sur le tLogRow pour relier les deux composants.
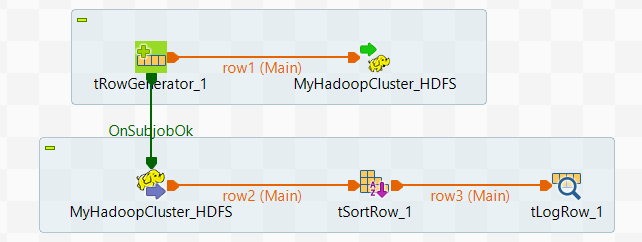
Votre espace de modélisation graphique (Designer) doit ressembler à ceci.
-
Cliquez sur le tLogRow pour relier les deux composants.
Résultats
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !