
Configurer le groupement des données de sortie
Procédure
-
Cliquez sur le composant tMatchGroup pour afficher sa vue Basic settings. Cliquez sur le bouton Edit schema afin de voir les colonnes d'entrée et de sortie, et d'effectuer des modifications dans le schéma de sortie, si nécessaire.
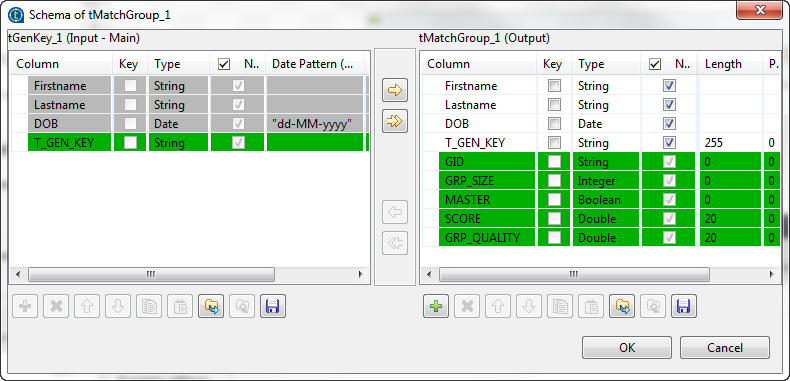 Dans le schéma de sortie de ce composant, des colonnes standards de sortie sont en lecture seule. Pour plus d'informations, consultez Propriétés du tMatchGroup Standard.
Dans le schéma de sortie de ce composant, des colonnes standards de sortie sont en lecture seule. Pour plus d'informations, consultez Propriétés du tMatchGroup Standard. -
Double-cliquez sur le composant tMatchGroup pour afficher l'assistant Configuration Wizard et configurer les propriétés du composant.
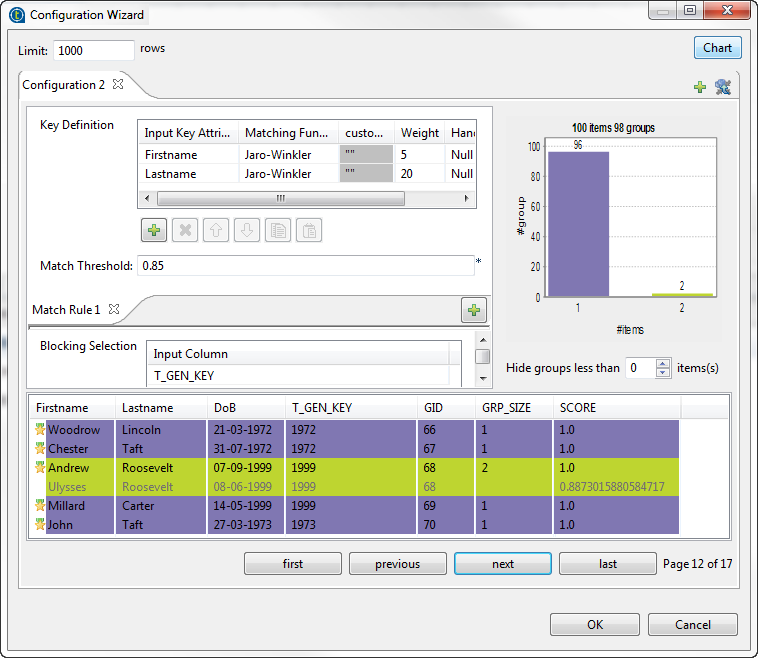 Si vous souhaitez ajouter une colonne de sortie fixe, MATCHING_DISTANCES, donnant les détails de la distance entre chaque colonne, cliquez sur l'onglet Advanced settings et cochez la case Output distance details. Pour plus d'informations, consultez Propriétés du tMatchGroup Standard.
Si vous souhaitez ajouter une colonne de sortie fixe, MATCHING_DISTANCES, donnant les détails de la distance entre chaque colonne, cliquez sur l'onglet Advanced settings et cochez la case Output distance details. Pour plus d'informations, consultez Propriétés du tMatchGroup Standard.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !