
Écrire en masse les données des films dans Neo4j
Procédure
-
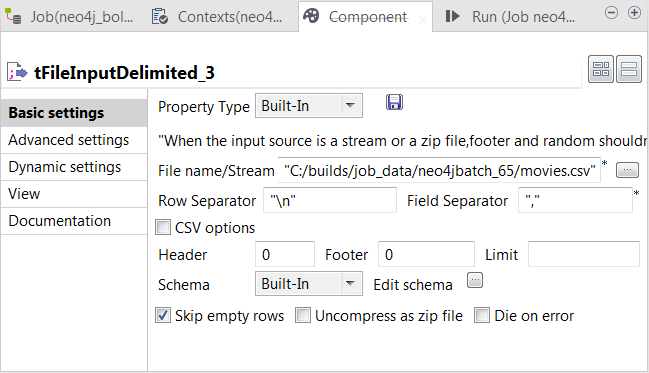
Double-cliquez sur le second tFileInputDelimited pour ouvrir sa vue Component.
-
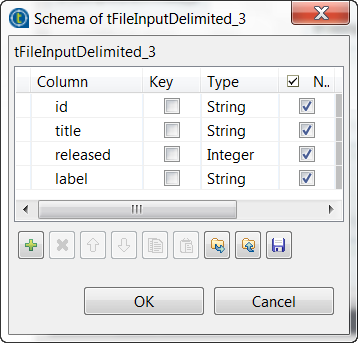
Cliquez sur le bouton [...] à côté du champ Edit schema pour ouvrir l'éditeur de schéma et définissez le schéma en vous basant sur la structure du fichier d'entrée.
Dans cet exemple, les colonnes sont id, title, released et label.
-
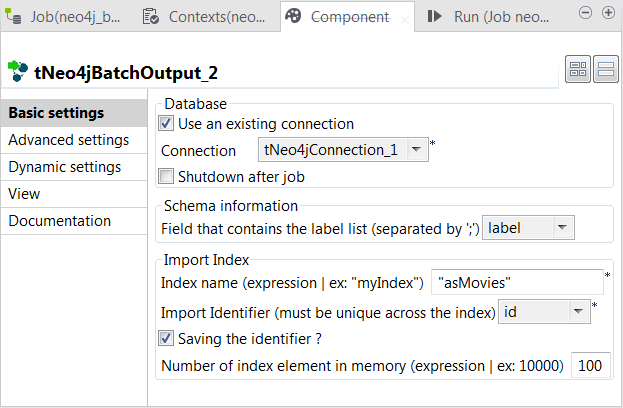
Double-cliquez sur le second tNeo4jBatchOutput pour ouvrir sa vue Component.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !