
Bulk-writing the movies data into Neo4j
Procedure
-
Double-click the second tFileInputDelimited component to open its Component view.
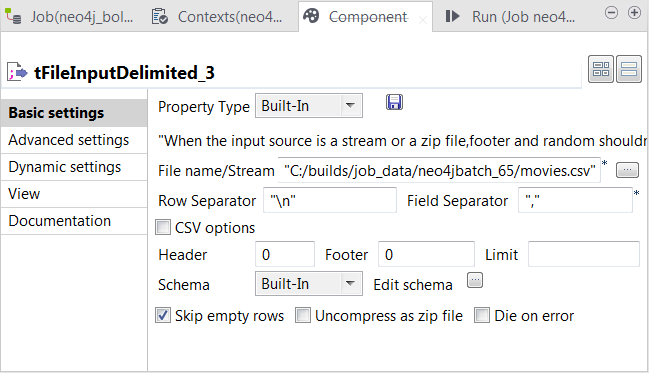
-
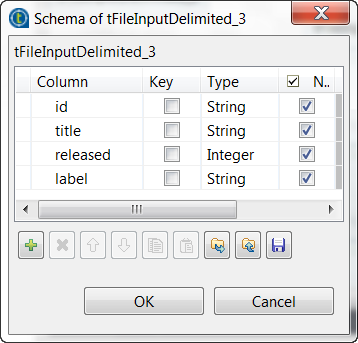
Click the [...] button next to Edit schema to open the schema editor, and define the input schema based on
the structure of the input file.
In this example, the columns are id, title, released and label.
-
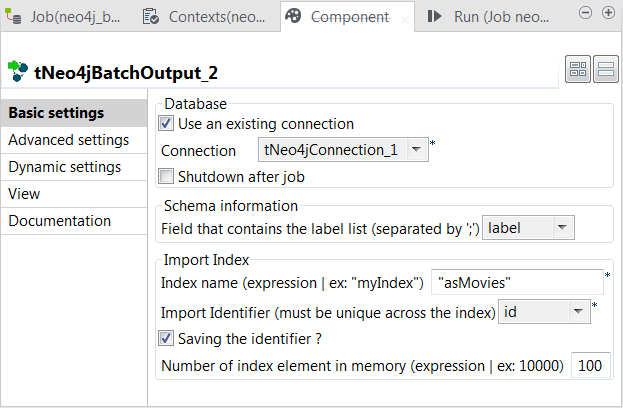
Double-click the second tNeo4jBatchOutput component to open its
Component view.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!