
Big Data
|
Fonctionnalité |
Description |
Disponible dans |
|---|---|---|
| Support de HPE Ezmeral Runtime Enterprise 5.4 sur Kubernetes avec Spark 3.1.x | Vous pouvez à présent exécuter vos Jobs Spark Batch et Streaming sur Kubernetes avec Livy et DataTap à l'aide de Spark Universal avec Spark 3.1.x.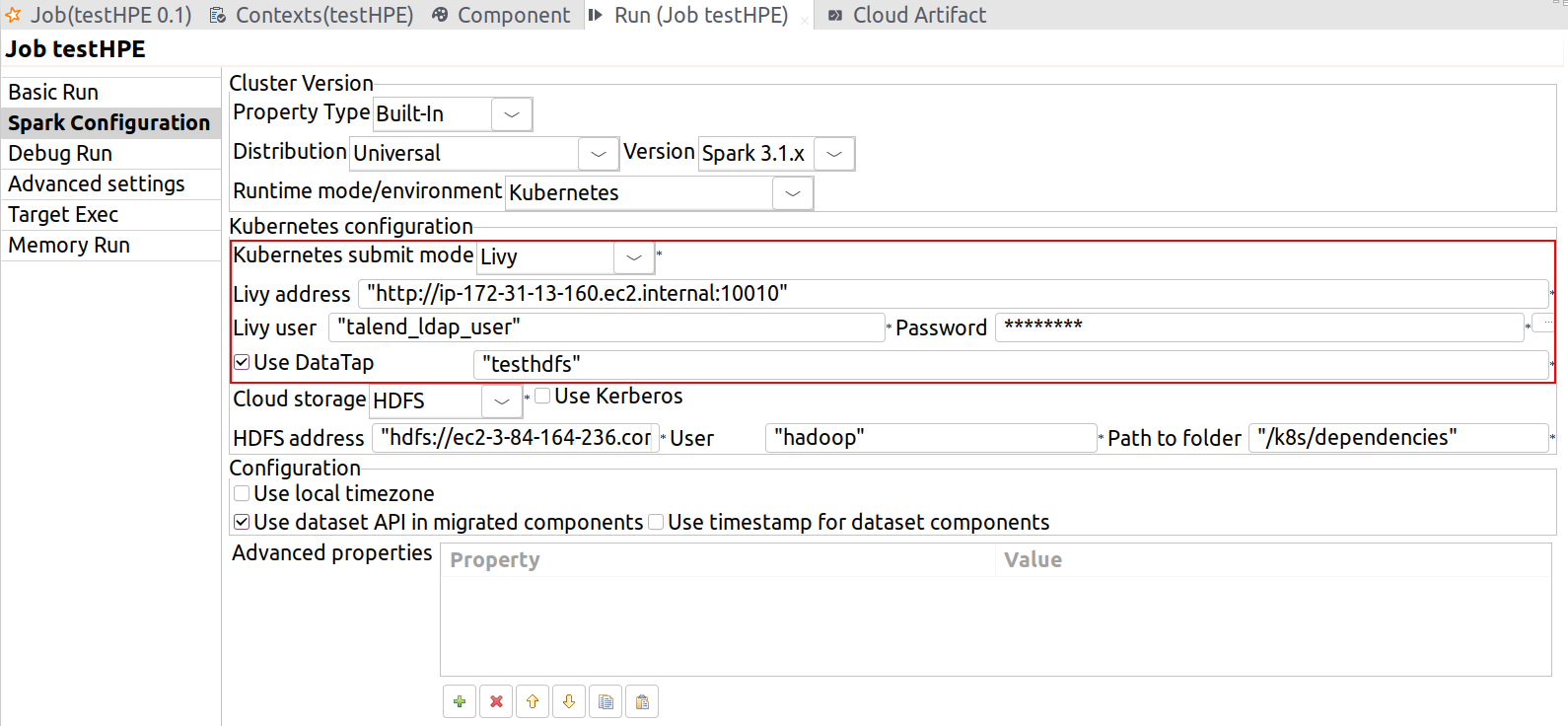
|
Tous les produits Talend avec Big Data nécessitant souscription |
| Support du Runtime Databricks 12.x avec Spark Universal 3.3.x | Vous pouvez à présent exécuter vos Jobs Spark Batch et Streaming sur des clusters universels et des clusters de jobs sur Google Cloud Platform (GCP), AWS et Azure à l'aide de Spark Universal avec Spark 3.3.x. Vous pouvez la configurer dans la vue Spark Configuration (Configuration de Spark) de vos Jobs Spark ou dans l'assistant de métadonnées Hadoop Cluster Connection (Connexion au cluster Hadoop). Lorsque vous sélectionnez ce mode, le Studio Talend est compatible avec la version 12.x de Databricks. 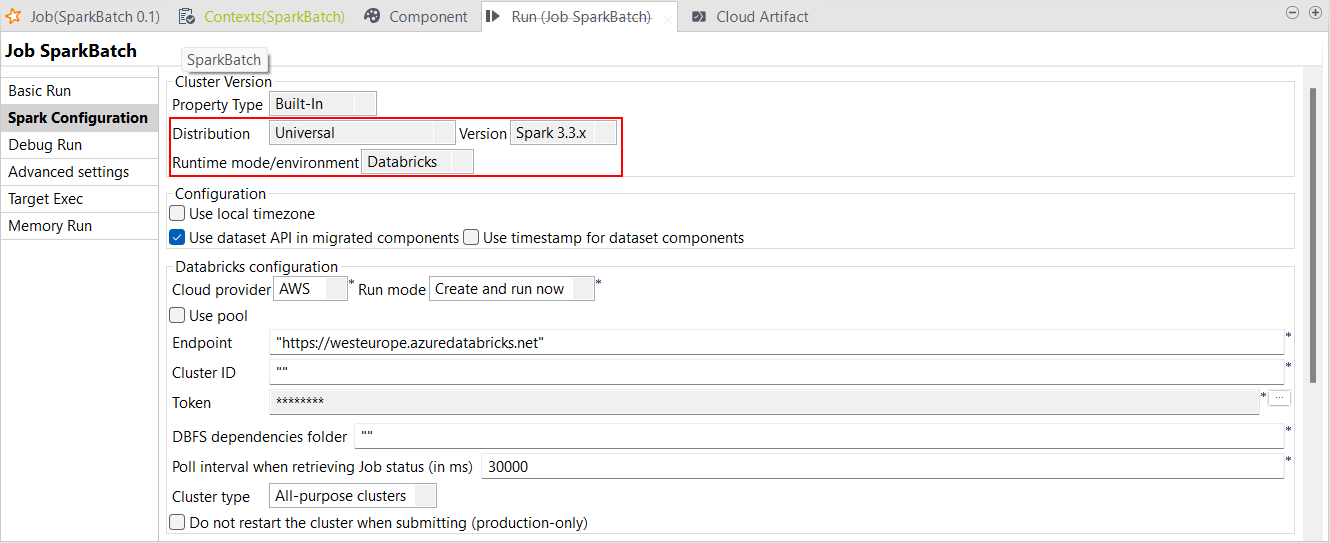
|
Tous les produits Talend avec Big Data nécessitant souscription |
| Support d'Amazon EMR 6.8.0 et 6.9.0 avec Spark Universal 3.3.x | Vous pouvez à présent exécuter vos Jobs Spark sur un cluster Amazon EMR, à l'aide de Spark Universal avec Spark 3.3.x en mode Yarn cluster. Vous pouvez la configurer dans la vue Spark Configuration (Configuration de Spark) de vos Jobs Spark ou dans l'assistant de métadonnées Hadoop Cluster Connection (Connexion au cluster Hadoop). Lorsque vous sélectionnez ce mode, le Studio Talend est compatible avec Amazon EMR 6.8.0 et 6.9.0. Avec la version Bêta de cette fonctionnalité, le problème connu suivant existe, avec une solution de contournement :
|
Tous les produits Talend avec Big Data nécessitant souscription |
| Support de MongoDB v4+ pour Spark Streaming 3.1 et versions supérieures | Le Studio Talend supporte à présent MongoDB v4+ avec Spark 3.1 et versions supérieures pour les composants suivants dans vos Jobs Spark Streaming utilisant Dataset :
Avec la version Bêta de cette fonctionnalité, la version de MongoDB à sélectionner dans la liste déroulante DB Version (Version de la BdD) est MongoDB 3.2+. |
Tous les produits Talend avec Big Data nécessitant souscription |
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !