
Traiter des données Parquet à l'aide de composants Snowflake
Ce scénario présente la manière de charger des données depuis un fichier Parquet dans une table Snowflake et de récupérer les données de la table Snowflake.
Pour plus de technologies supportées par Talend, consultez Composants Talend.
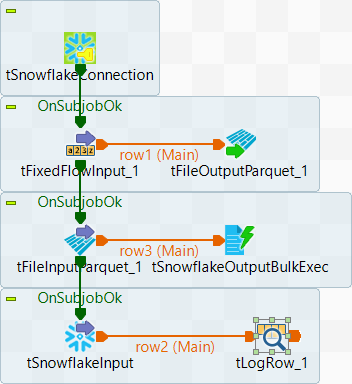
Le Job de ce scénario comprend quatre sous-Jobs. Le premier sous-Job établit une connexion à Snowflake. Le deuxième sous-Job écrit des données dans un fichier Parquet et stocke le fichier sur la machine locale. Le troisème sous-Job récupère des données du fichier Parquet et charge les données dans une table Snowflake. Le quatrième sous-Job récupère les données de la table dans laquelle les données sont chargées et les affiche dans la console. La capture d'écran suivante présente le Job utilisé dans ce scénario.
Ce scénario présuppose que vous avez les informations d'authentification et les droits nécessaires pour vous connecter à la base de données Snowflake.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !