
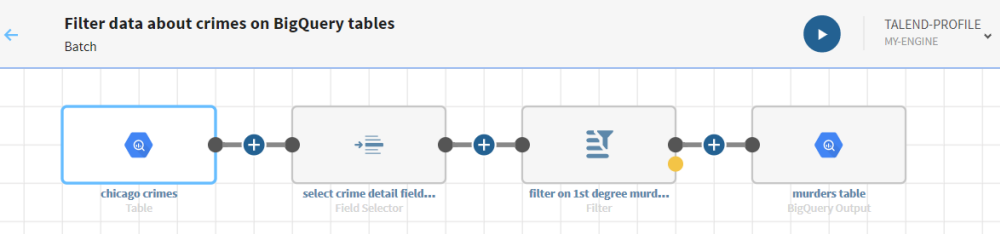
Filtrer des données relatives aux crimes dans des tables Google BigQuery
Ce scénario a pour objectif de vous aider à configurer et à utiliser des connecteurs dans un pipeline. Ce scénario doit être adapté en fonction de votre environnement et de votre cas d'utilisation.
Avant de commencer
-
Si vous souhaitez reproduire ce scénario, vous pouvez utiliser le jeu de données BigQuery disponible chicago_crime gratuitement.
Procédure
-
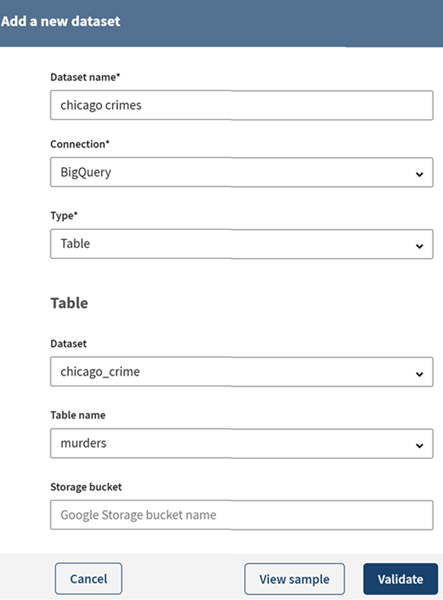
Renseignez les propriétés requises pour accéder au fichier situé dans votre bucket BigQuery (nom du jeu de données, nom de la table ou requête) et cliquez sur View sample (Voir l'échantillon) pour voir un aperçu de l'échantillon de données.
-
Cliquez sur
 et ajoutez un processeur Field selector au pipeline. Le panneau de configuration s'ouvre.
et ajoutez un processeur Field selector au pipeline. Le panneau de configuration s'ouvre.
-
Cliquez sur et ajoutez un processeur Filter au pipeline. Donnez-lui un nom significatif.
Exemple
filter on 1st degree murders -
(Facultatif) Consultez l'aperçu du processeur Filter pour voir l'échantillon de données après l'opération de filtre.
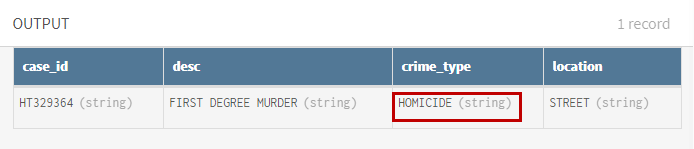
Résultats
Votre pipeline est en cours d'exécution. Les données relatives aux crimes ont été traitées, les cas d'homicides ont été isolés et le flux de sortie est envoyé dans la table Google BigQuery indiquée.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !