
Découvrir des types sémantiques
La découverte de données calcule combien de valeurs correspondent à chaque type sémantique et, si le résultat est supérieur à 40 %, elle attribue le type sémantique à la colonne.
Pour afficher le pourcentage de chaque type sémantique, dans la vue de l'échantillon de votre jeu de données, cliquez sur l'icône ![]() .
.
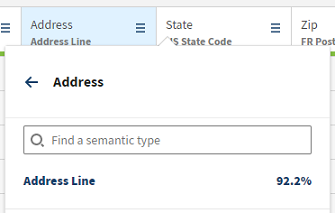
Cette fonctionnalité est également disponible depuis la vue Hierarchy (Hiérarchie).
Comment le pourcentage est-il calculé ?
-
Un pourcentage représente le nombre de valeurs correspondant au type sémantique ; jusqu'à 100 % alloués.
Pour déterminer si une valeur correspond à un type sémantique, la découverte de données dépend du type du type sémantique :
- Dictionnaire : La valeur correspond-elle à une valeur du dictionnaire ? La ponctuation, la casse, les espaces et les accents sont ignorés.
- Regular expression (Expression régulière) : La valeur correspond-elle à l'expression régulière ?
- Compound (Composé·e) : La valeur est-elle découverte dans au moins un enfant ?Un type composé est un groupe de types sémantiques existants, appelés enfants.
Si la réponse est positive, la valeur est considérée comme valide.
- L'autre pourcentage représente la similarité entre le nom de colonne et le nom du type sémantique ; jusqu'à 10 % alloués. Pour comparer les noms :Le pourcentage maximal est de 100 %. Si toutes les valeurs correspondent à un type sémantique et que le nom de colonne est identique au nom du type sémantique, le résultat est toujours de 100 %.
- C'est l'algorithme de Levenshtein qui est utilisé. Il calcule le nombre minimal de modifications (insertions, suppressions ou substitutions) nécessaires à la transformation d'une chaîne de caractères en une autre.
- La casse et les accents sont ignorés.
- Si les chaînes de caractères contiennent des espaces, l'ordre des mots est ignoré. Par exemple, US Phone et Phone US sont considérés comme identiques.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !