
Parser des champs JSON et XML
Avant de commencer
-
Vous avez précédemment ajouté le jeu de données contenant vos données source.
Ici, un jeu de données avec des champs JSON et XML contenant des données concernant les utilisateurs et utilisatrices, y compris leur nom et leur adresse :
Téléchargez le fichier unparsed-users.csv.
Importez-le en tant que jeu de données local et configurez le champ Header (En-tête) à 1 pour indiquer que la première ligne du fichier est en un-tête.
-
Vous avez créé la connexion et le jeu de données associé qui contiendra les données traitées.
Ici, un jeu de données Test.
Procédure
-
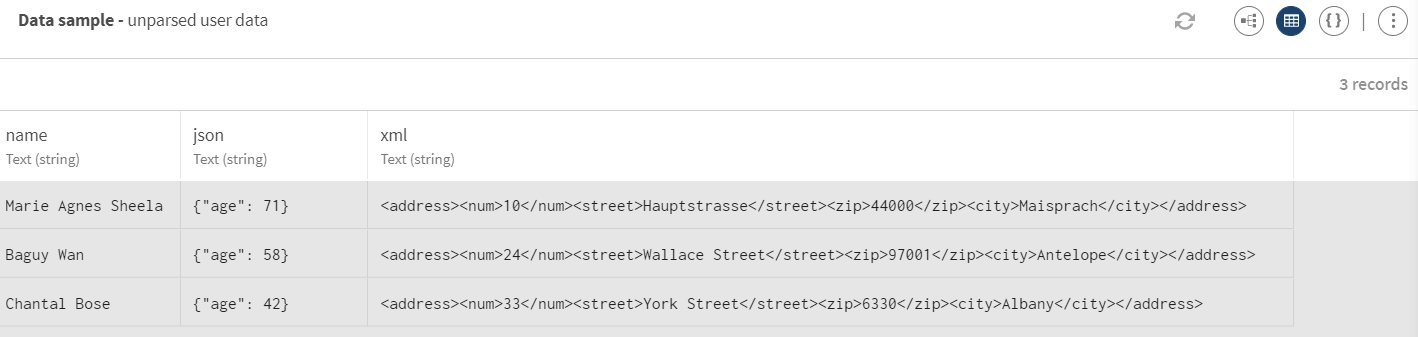
Cliquez sur ADD SOURCE pour ouvrir le panneau vous permettant de sélectionner vos données source, ici, un mélange de données utilisateur·trices JSON et XML non parsées saisies manuellement en tant que jeu de données de test.
-
Cliquez sur le bouton
 et ajoutez un processeur Parser au pipeline. Le panneau de configuration s'ouvre.
et ajoutez un processeur Parser au pipeline. Le panneau de configuration s'ouvre.
-
Dans la zone Configuration :
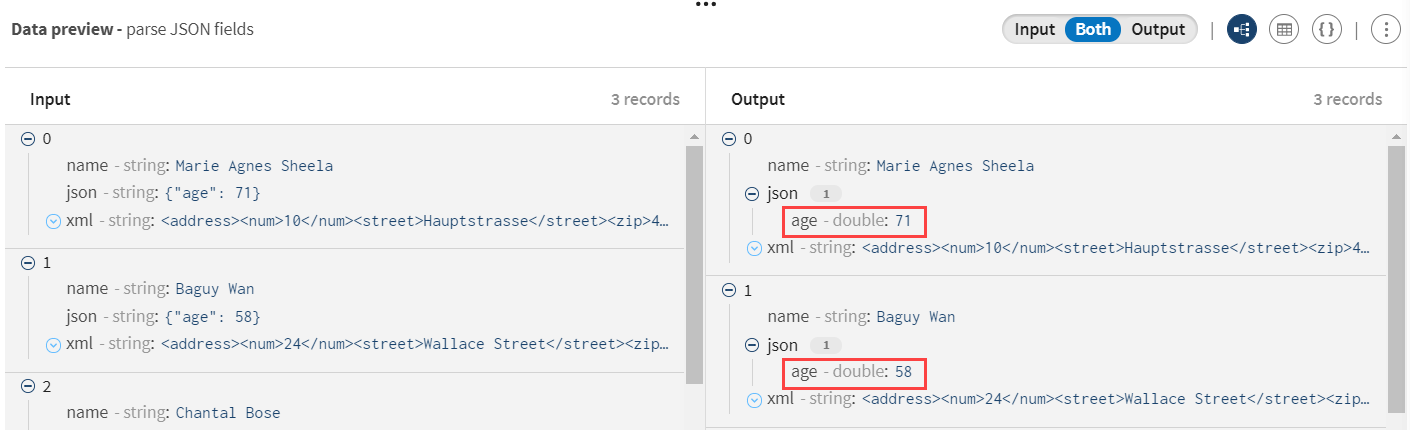
- Sélectionnez JSON dans la liste Format car vous souhaitez d'abord parser les champs JSON d'entrée.
- Sélectionnez .json dans la liste Field to process (Champ à traiter), car vous souhaitez transformer les champs JSON correspondant à l'âge des utilisateur·trices.
- Activez Enforce number as double (Implémenter le nombre comme un double) pour vous assurer que les nombres d'entrée, comme l'âge, sont convertis en type de données Double.
Examinez la prévisualisation du processeur afin de comparer vos données avant et après l'opération de parsing.
-
Cliquez sur le bouton et ajoutez un processeur Parser au pipeline. Le panneau de configuration s'ouvre.
-
Cliquez sur Save (Sauvegarder) pour sauvegarder votre configuration.
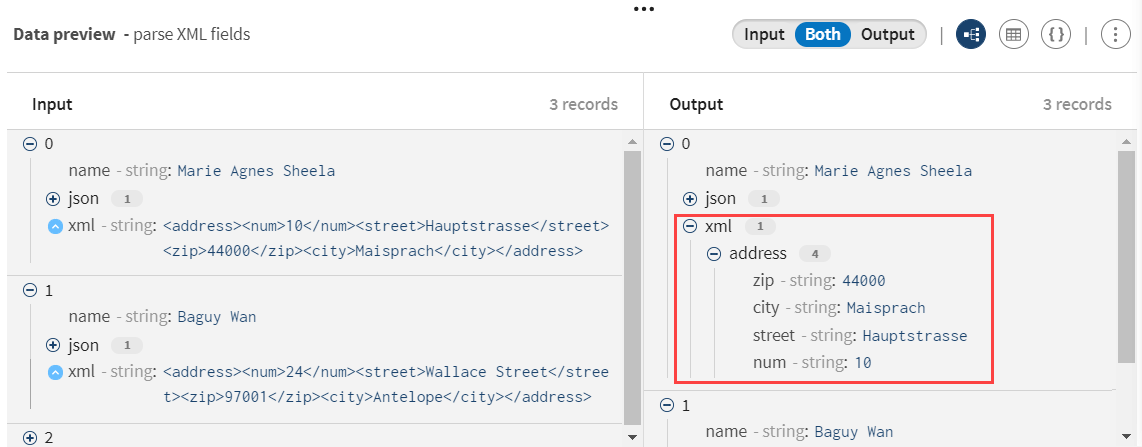
Examinez la prévisualisation du processeur afin de comparer vos données avant et après l'opération de parsing.
Résultats
Votre pipeline est en cours d'exécution. Les champs JSON et XML d'entrée ont été parsés et transformés en objets JSON et XML.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !