
Traiter une liste d'appareils d'utilisateurs et d'utilisatrices avec des requêtes
Avant de commencer
-
Vous avez précédemment créé une connexion au système stockant vos données source.
Ici, une connexion de test.
-
Vous avez précédemment ajouté le jeu de données contenant vos données source.
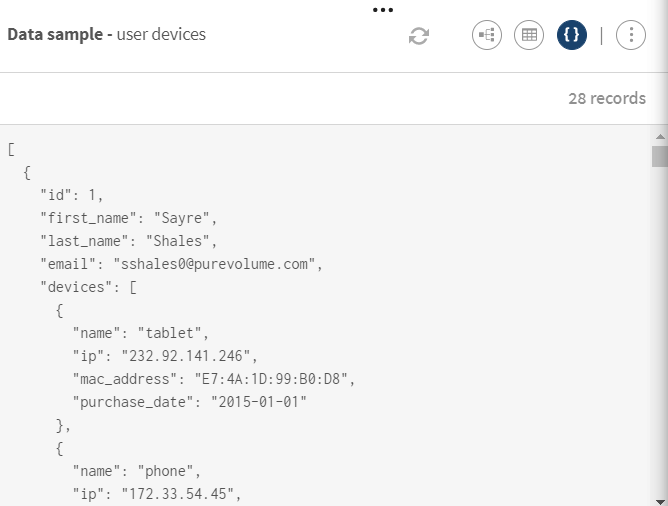
Téléchargez et extrayez le fichier query_language-devices.zip. Il contient un fichier .json hiérarchique relatif à un sondage concernant les appareils des utilisateur·trices, notamment le type d'appareil, la date d'achat ou encore les adresses IP.
-
Vous avez créé la connexion et le jeu de données associé qui contiendra les données traitées.
Ici, un fichier stocké dans un bucket S3.
Procédure
-
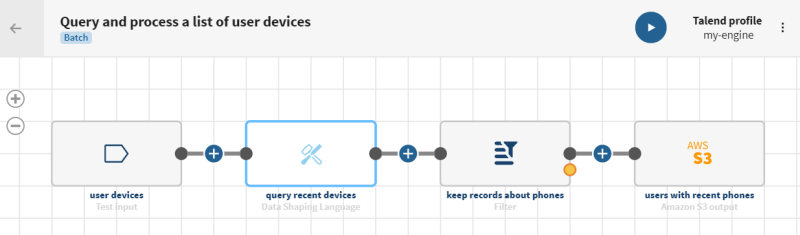
Cliquez sur ADD SOURCE (AJOUTER UNE SOURCE) pour ouvrir le panneau vous permettant de sélectionner vos données source, ici un sondage sur les appareils d'utilisateurs et d'utilisatrices avec des données hiérarchiques.
Exemple
-
Cliquez sur le bouton
 et ajoutez un processeur Data Shaping Language au pipeline. Le panneau de Configuration s’affiche.
et ajoutez un processeur Data Shaping Language au pipeline. Le panneau de Configuration s’affiche.
-
Cliquez sur Save (Sauvegarder) pour sauvegarder votre configuration.
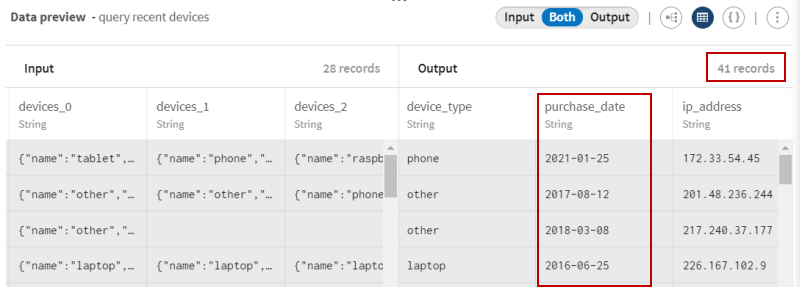
L'aperçu vous permet de visualiser la nouvelle structure : Maintenant que la structure est aplatie, un plus grand nombre d'enregistrements est écrit en sortie et seuls les appareils acquis après le 1er janvier 2015 s'affichent.
-
Cliquez sur le bouton et ajoutez un processeur Filter au pipeline. Le panneau de Configuration s’affiche.
-
Dans la zone Filter :
-
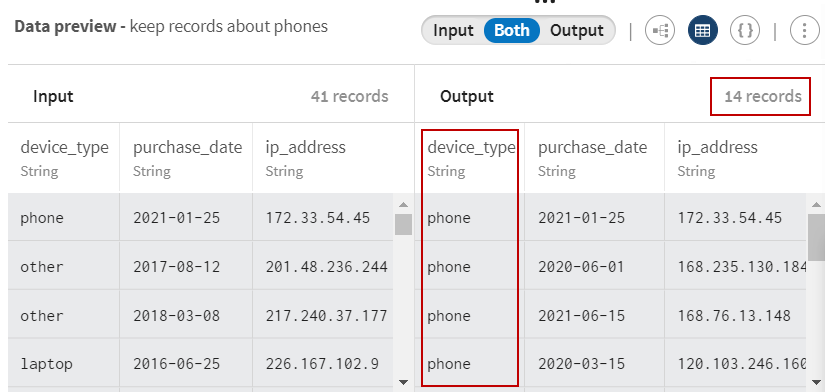
Cliquez sur Save (Sauvegarder) pour sauvegarder votre configuration. L'aperçu vous permet de visualiser les enregistrements correspondant aux critères de filtre (les utilisateurs et utilisatrices avec un téléphone).
-
Cliquez sur Save (Sauvegarder) pour sauvegarder votre configuration. L'aperçu vous permet de visualiser les enregistrements correspondant aux critères de filtre (les utilisateurs et utilisatrices avec un téléphone).
Résultats
Votre pipeline est en cours d’exécution. Les données sont traitées selon les conditions spécifiées à l'aide du langage de requête et la sortie est envoyée vers le système cible spécifié.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !