
Traiter des données de streaming d'avions

Avant de commencer
-
Vous avez précédemment créé une connexion au système stockant vos données source.
-
Vous avez précédemment ajouté le jeu de données contenant vos données source.
Ici, les données de streaming des avions comprennent l'identifiant des avions, leur position et la date et l'heure.
Pour vous aider à comprendre ce scénario, vous trouverez ci-dessous le schéma Avro des données de streaming utilisées dans ce scénario :{ "type": "record", "name": "aircrafts", "fields": [ {"name": "Id", "type": "int"}, {"name": "PosTime", "type": "long"}, {"name": "Lat", "type": "double"}, {"name": "Long", "type": "double"}, {"name": "Op", "type": "string"} ] }où Id correspond aux identifiants des avions, PosTime à la date et l'heure de la position, Lat/Long à la latitude et à la longitude des avions, et Op aux compagnies aériennes.
-
Vous avez créé la connexion et le jeu de données associé qui contiendra les données traitées.
Ici, une table MySQL.
Procédure
-
Cliquez sur ADD SOURCE pour ouvrir le panneau vous permettant de sélectionner vos données source, ici le topic sur les avions sur Kafka.
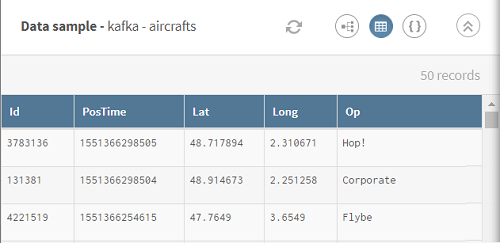
-
Cliquez sur le bouton
 et ajoutez un processeur Window (Fenêtre) au pipeline. Le panneau de configuration s'ouvre.
et ajoutez un processeur Window (Fenêtre) au pipeline. Le panneau de configuration s'ouvre.
-
Cliquez sur le bouton et ajoutez un processeur Aggregate au pipeline. Le panneau de configuration s'ouvre.
-
Cliquez sur le bouton et ajoutez un processeur Field Selector au pipeline. Le panneau de configuration s'ouvre.
-
Cliquez sur le bouton et ajoutez un processeur Python 3 au pipeline. Le panneau de configuration s'ouvre.
-
(Facultatif) Examinez la prévisualisation du processeur Python 3 afin de prévisualiser vos données.
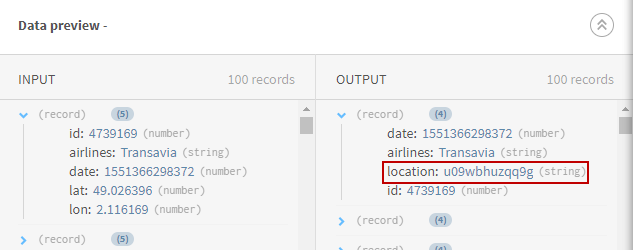
Résultats
Votre pipeline de streaming est en cours d'exécution et sera exécuté jusqu'à ce que vous l'arrêtiez. Les données des avions sont modifiées et les informations des geohashes calculés sont envoyés au système cible que vous avez spécifié.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !