
Big Data
|
機能 |
説明 |
対象製品 |
|---|---|---|
| Spark 3.1.xを使ったKubernetesでHPE Ezmeral Runtime Enterprise 5.4をサポート | Spark 3.1.xと共にSpark Universalを使い、LivyとDataTapによるKubernetesでSpark BatchジョブとStreamingジョブを実行できるようになりました。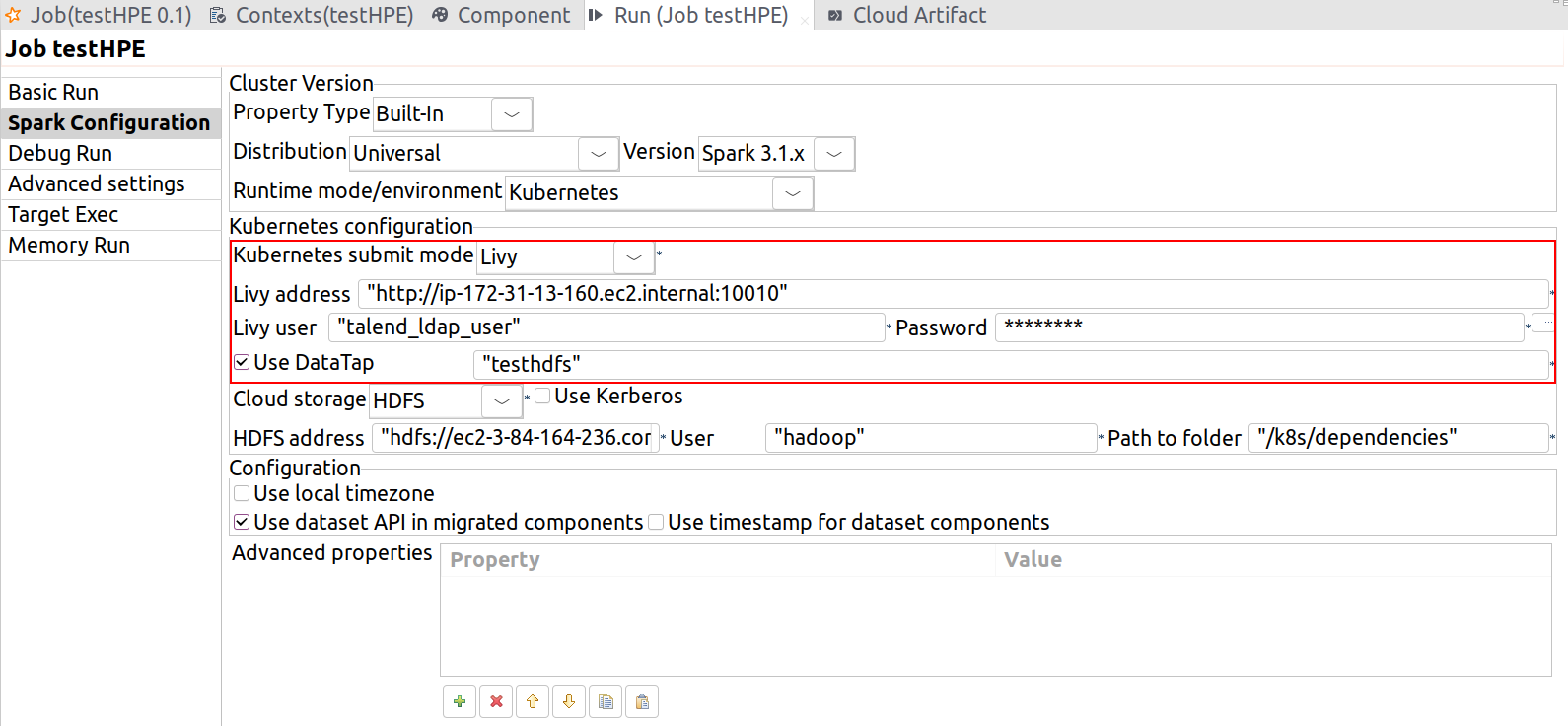
|
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
| Spark Universal 3.3.xでDatabricks 12.xランタイムをサポート | Spark 3.3.xと共にSpark Universalを使い、Google Cloud Platform (GCP)、AWS、Azureでの汎用クラスターとジョブクラスターでSpark BatchジョブとSpark Streamingジョブを実行できるようになりました。Sparkジョブの[Spark configuration] (Spark設定)ビューまたは[Hadoop Cluster Connection] (Hadoopクラスター接続)メタデータウィザードのどちらかで設定できます。 このモードを選択すると、Talend StudioはDatabricks 12.xのバージョンと互換性を持つようになります。 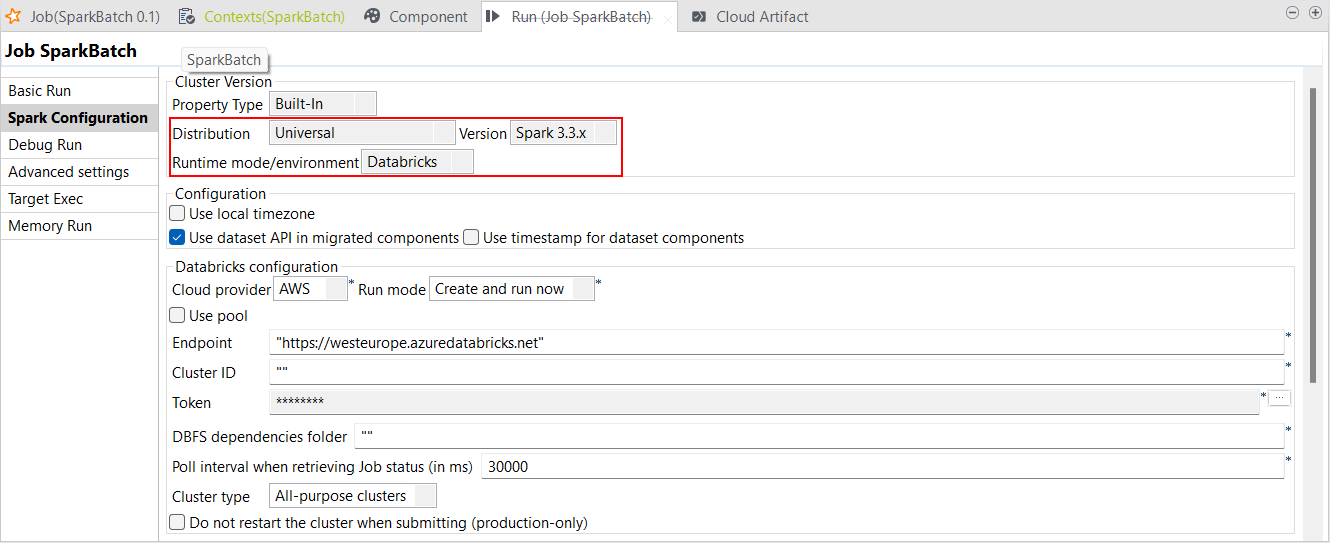
|
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
| Spark Universal 3.3.xでAmazon EMR 6.8.0と6.9.0をサポート | YarnクラスターモードでSpark 3.3.xと共にSpark Universalを使い、Amazon EMRクラスターでSparkジョブを実行できるようになりました。Sparkジョブの[Spark configuration] (Spark設定)ビューまたは[Hadoop Cluster Connection] (Hadoopクラスター接続)メタデータウィザードのどちらかで設定できます。 このモードを選択すると、Talend Studioは Amazon EMRのバージョン6.8.0および6.9.0と互換性を持つようになります。 この機能のベータ版には次のような既知の問題がありますが、回避策もあります。
|
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
| Spark Streaming 3.1以降でMongoDB v4+をサポート | データセットを使ったSpark Streamingジョブの次のコンポーネントで、Talend StudioでSpark 3.1以降のバージョンを使用するMongoDB v4+がサポートされました。
この機能のベータ版では、[DB Version] (DBバージョン)ドロップダウンリストから選択するMongoDBバージョンはMongoDB 3.2+です。 |
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。