
Analyser un flux Twitter en quasi temps réel
Ce scénario s'applique uniquement aux solutions Talend Real-Time Big Data Platform et Talend Data Fabric.
Pour plus de technologies supportées par Talend, consultez Composants Talend.
Dans ce scénario, vous créez un Job Spark Streaming pour analyser, après chaque intervalle de 15 secondes, les hashtags les plus utilisés par les utilisateurs et utilisatrices de Twitter lorsqu'ils mentionnent Paris, au cours de la période des 20 secondes précédentes.
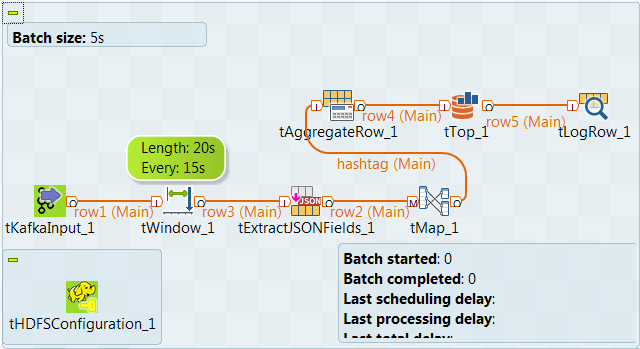
Un programme tiers open source est utilisé pour recevoir et écrire des flux Twitter dans un sujet Kafka donné, twitter_live par exemple et le Job que vous créez dans ce scénario est utilisé pour consommer les Tweets de ce sujet.
Une ligne de données brutes Twitter avec des hashtags se présente comme exemple à l'adresse suivante https://dev.twitter.com/overview/api/entities-in-twitter-objects#hashtags (en anglais).
Avant de reproduire ce scénario, vous devez vous assurer que votre système Kafka s'exécute correctement et que vous avez les droits et autorisations appropriés pour accéder au sujet Kafka à utiliser. Vous avez besoin d'un programme de mise en flux de Twitter afin de transférer des flux Twitter dans Kafka en quasi temps réel. Talend ne fournit pas ce genre de programme mais certains programmes gratuits, créés à cet effet, sont disponibles sur des communautés en ligne, comme Github.
Le tHDFSConfiguration est utilisé dans ce scénario par Spark afin de se connecter au système HDFS où sont transférés les fichiers Jar dépendant du Job.
-
Yarn mode (Yarn Client ou Yarn Cluster) :
-
Lorsque vous utilisez Google Dataproc, spécifiez un bucket dans le champ Google Storage staging bucket de l'onglet Spark configuration.
-
Lorsque vous utilisez HDInsight, spécifiez le blob à utiliser pour le déploiement du Job, dans la zone Windows Azure Storage configuration de l'onglet Spark configuration.
- Lorsque vous utilisez Altus, spécifiez le bucket S3 ou le stockage Azure Data Lake Storage (aperçu technique) pour le déploiement du Job, dans l'onglet Spark configuration.
- Lorsque vous utilisez Qubole, ajoutez tS3Configuration à votre Job pour écrire vos données métier dans le système S3 avec Qubole. Sans tS3Configuration, ces données métier sont écrites dans le système Qubole HDFS et détruites une fois que vous arrêtez votre cluster.
-
Lorsque vous utilisez des distributions sur site (on-premises), utilisez le composant de configuration correspondant au système de fichiers utilisé par votre cluster. Généralement, ce système est HDFS et vous devez utiliser le tHDFSConfiguration.
-
-
Standalone mode : utilisez le composant de configuration correspondant au système de fichiers que votre cluster utilise, comme le tHDFSConfiguration Apache Spark Batch ou le tS3Configuration Apache Spark Batch.
Si vous utilisez Databricks sans composant de configuration dans votre Job, vos données métier sont écrites directement dans DBFS (Databricks Filesystem).
Pour reproduire ce scénario, procédez comme suit :
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !