
Verwenden von Versionen in Talend-Jobs
Versionen von Datenaufbereitungen können in Studio Talend sowohl in Data Integration- als auch in Big Data-Jobs verwendet werden.
In Studio Talend ermöglicht Ihnen die tDataprepRun-Komponente die Wiederverwendung einer Datenaufbereitung oder einer ihrer Versionen sowie deren Anwendung auf Daten mit demselben Modell.
Sie können eine Datenaufbereitung natürlich jederzeit in ihrem aktuellen Status verwenden, durch die Verwendung einer spezifischen Version lässt sich jedoch sicherstellen, dass in Ihren Jobs stets derselbe Status einer Datenaufbereitung zum Einsatz kommt, selbst wenn die Datenaufbereitung nach wie vor bearbeitet wird. Dadurch kann verbesserte Konsistenz gewährleistet werden.
Das folgende Beispiel illustriert einen Job, der eine vorhandene Datenaufbereitungsversion auf eine Salesforce-Eingabe anwendet und das Ergebnis in einer Redshift-Datenbank ausgibt.
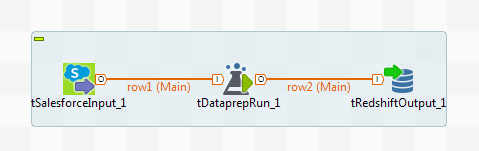
Diese Datenaufbereitung wurde ausgehend von einem Datensatz erstellt, der grundlegende Kundendaten enthält, wie z. B. Namen, Telefonnummern und E-Mailadressen. Es wurden ein paar Schritte angewendet, um Formatierungsfehler in den Namenseinträgen zu entfernen und ungültige Werte aus den Telefonnummern zu löschen.
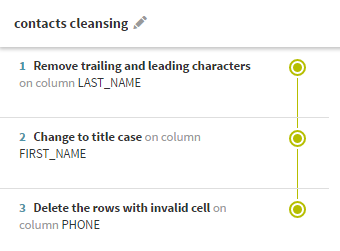
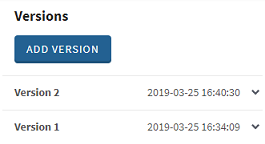
Bei der Datenaufbereitung wurden zwei Versionen erstellt: Eine nach den ersten zwei Schritten und eine weitere nach den dritten Schritt.
Vorbereitungen
- Sie haben eine Datenaufbereitung mit mindestens einer Version in Talend Cloud Data Preparation erstellt. In diesem Fall weist die vorhandene Datenaufbereitung den Namen contacts cleansing (Kontaktbereinigung) auf.
- Die aus Salesforce importierten Daten müssen über dasselbe Schema verfügen wie der zur ursprünglichen Erstellung der Datenaufbereitung verwendete Datensatz.
Prozedur
-
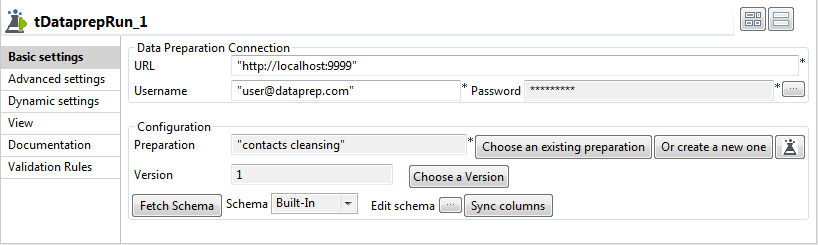
Wählen Sie die Komponente tDataprepRun aus und klicken Sie auf die Registerkarte Component, um deren Basiseinstellungen zu definieren.
-
Klicken Sie auf Choose an existing preparation (Vorhandene Datenaufbereitung auswählen), um die Liste der in Talend Cloud Data Preparation verfügbaren Datenaufbereitungen anzuzeigen.
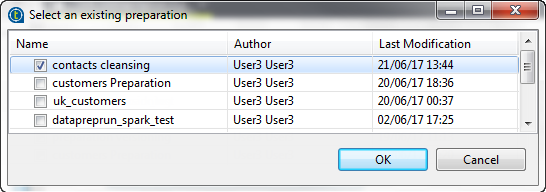
-
Klicken Sie auf choose a version (Version auswählen), um in der Liste der verfügbaren Versionen eine Auswahl für Ihre Datenaufbereitung zu treffen. Wählen Sie in diesem Fall Version 1 aus.
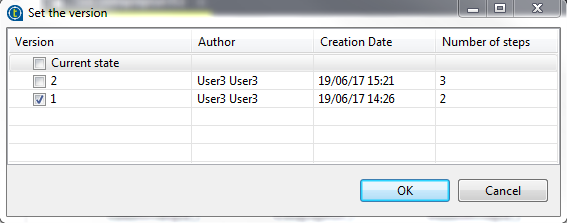
Standardmäßig verwendet der Job die Version current state (Aktueller Status) der ausgewählten Datenaufbereitung. Die Verwendung von current state (Aktueller Status) anstelle einer bestimmten Version bedeutet im Kontext von Zusammenarbeit, dass jemand eventuell Änderungen an der Datenaufbereitung vorgenommen hat und Sie davon keine Kenntnis haben.lei Infolgedessen können Sie nicht genau wissen, welches Ergebnis Ihr Job erzielen wird. Aus diesem Grund ist es sicherer, eine bestimmte Version in Ihren Jobs zu verwenden.
Ergebnisse
Alle in der Version der Datenaufbereitung enthaltenen Datenaufbereitungsschritte werden direkt im Flow des Jobs auf Ihre Daten angewendet.
Hat diese Seite Ihnen geholfen?
Wenn Sie Probleme mit dieser Seite oder ihren Inhalten feststellen – einen Tippfehler, einen fehlenden Schritt oder einen technischen Fehler –, teilen Sie uns bitte mit, wie wir uns verbessern können!