
Apprentissage du modèle d'arbre de décision
Cette section présente l'apprentissage de votre modèle d'arbre de décision.
Procédure
-
Laissez la valeur par défaut des autres paramètres.
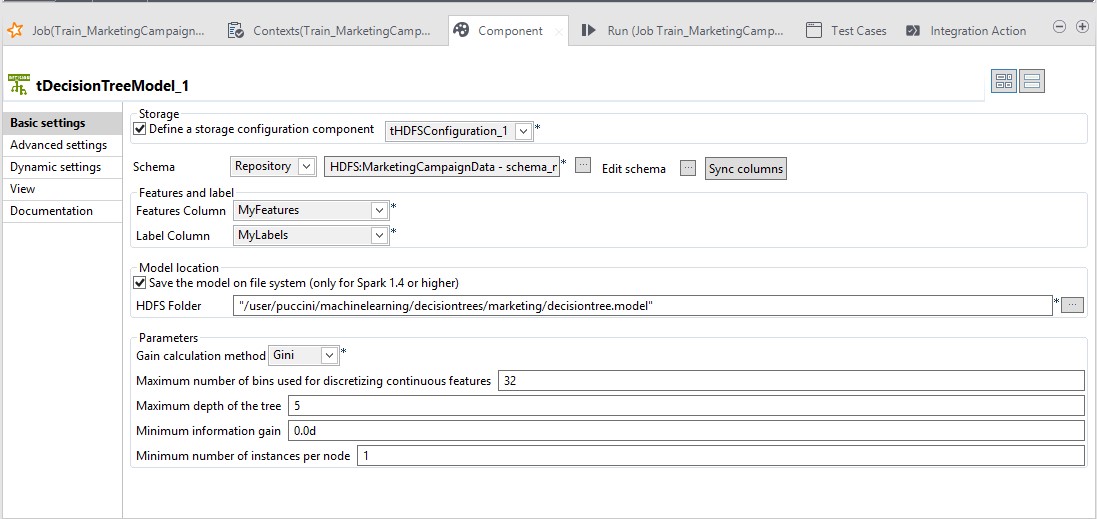
Voici la configuration du Job.
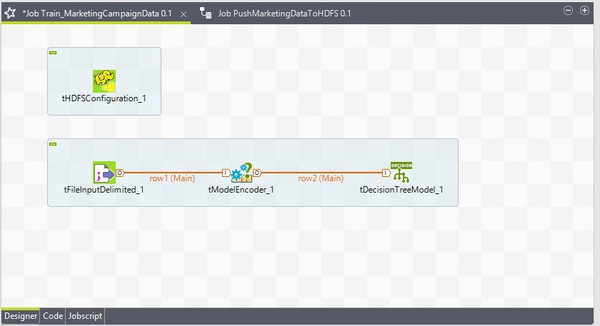
-
Cochez la case Use local mode.
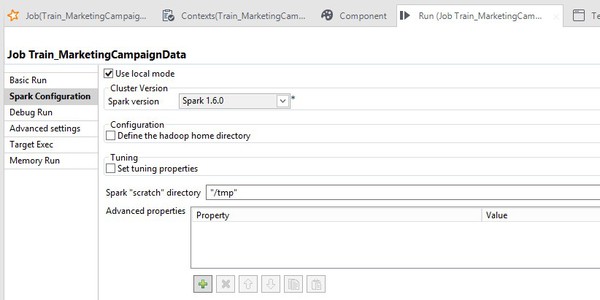 Vous pouvez également exécuter ce Job directement dans le cluster Hadoop, cas le plus probable dans des situations de production. Pour cela, vous devez apporter quelques ajustements à la manière dont le Job s'exécute, y compris décocher la case Use local mode.
Vous pouvez également exécuter ce Job directement dans le cluster Hadoop, cas le plus probable dans des situations de production. Pour cela, vous devez apporter quelques ajustements à la manière dont le Job s'exécute, y compris décocher la case Use local mode.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !