
Configurer la standardisation des données non structurées
Pourquoi et quand exécuter cette tâche
Pour définir un espace de noms :
Procédure
-
Double-cliquez sur le composant tStandardizeRow pour afficher sa vue Basic settings.
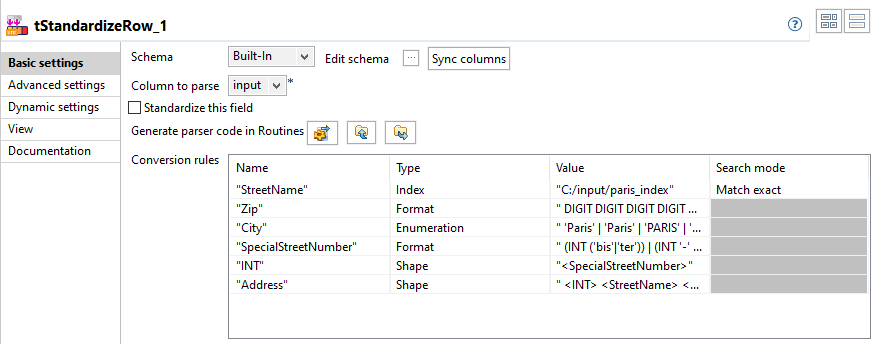 Les règles de type avancé sont toujours exécutées après les règles spécifiques ANTLR.
Les règles de type avancé sont toujours exécutées après les règles spécifiques ANTLR. -
Double-cliquez sur le tLogRow lié au tStandardizeRow afin d'afficher sa vue Basic settings.

Résultats
Configurez le filtrage et l'extraction des données qui vous intéressent.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !