
Creating the Big Data Batch Job
Create a Job with a tHMapInput and two output components to convert a JSON file to two CSV files.
About this task
This example uses a local file as input, but you can also create an HDFS connection. For more information, see HDFS components.
Procedure
-
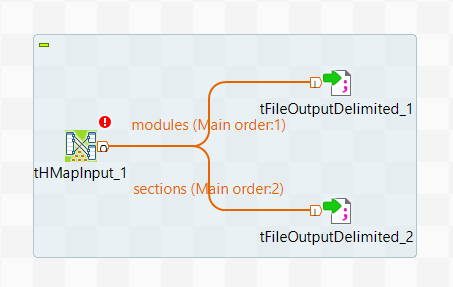
Link the tHMapInput to
the two tFIleOutputDelimited components with connections named modules
and sections and click Yes when asked if you want to get the schema
from the target component.
Your Job should look like this:
-
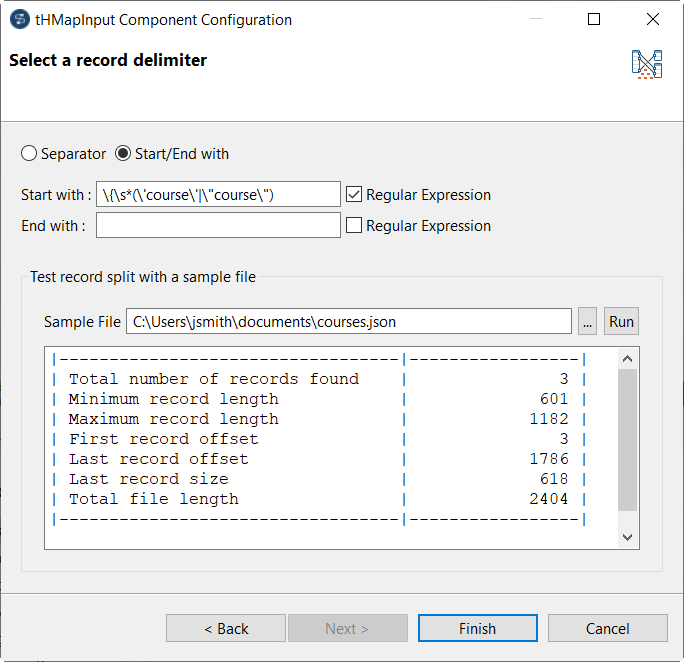
Double-click the tHMapInput and follow
the wizard to generate the map.
- Optional:
Click the ...
button to add your sample input file and click Run to check the records found.
In this case, you should have three records.
Example
- Optional:
Click the ...
button to add your sample input file and click Run to check the records found.
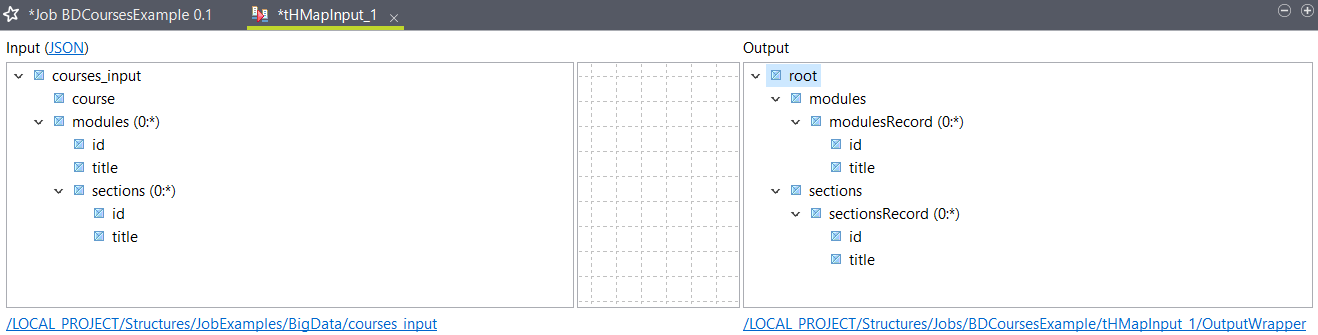
Results
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!