
Créer le Job Big Data Batch
Créez un Job avec un tHMapInput et deux composants de sortie afin de convertir un fichier JSON en deux fichiers CSV.
Pourquoi et quand exécuter cette tâche
Cet exemple utilise un fichier local en entrée, mais vous pouvez également créer une connexion à HDFS. Pour plus d'informations, consultez Composants HDFS (uniquement en anglais).
Procédure
-
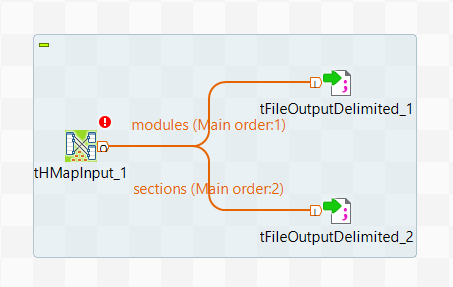
Reliez le tHMapInput aux deux composants tFIleOutputDelimited à l'aide de liens nommés modules et sections, puis cliquez sur Yes lorsqu'il vous est proposé de récupérer le schéma du composant cible.
Votre Job doit ressembler à ceci :
-
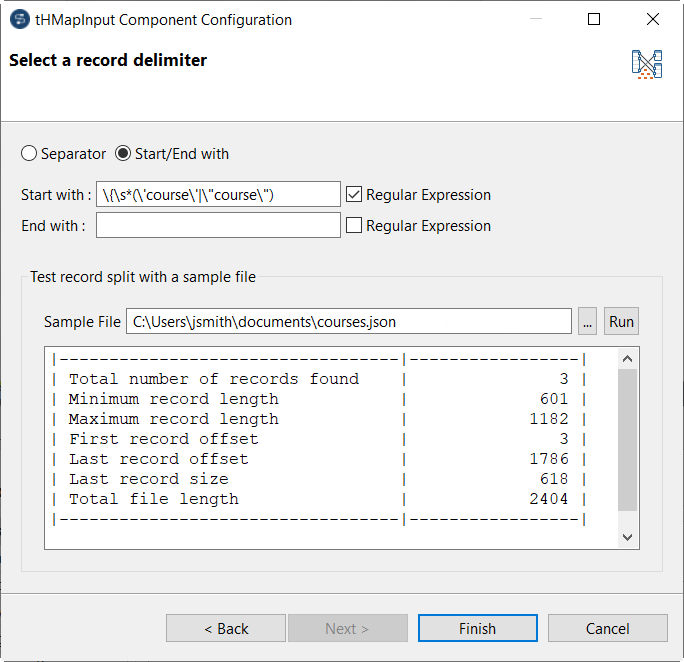
Double-cliquez sur le tHMapInput et suivez l'assistant pour générer la map.
- Facultatif :
Cliquez sur le bouton ... pour ajouter votre fichier échantillon d'entrée et cliquez sur Run pour voir le nombre d'enregistrements trouvés.
Dans ce cas, vous devez avoir trois enregistrements.
Exemple
- Facultatif :
Cliquez sur le bouton ... pour ajouter votre fichier échantillon d'entrée et cliquez sur Run pour voir le nombre d'enregistrements trouvés.
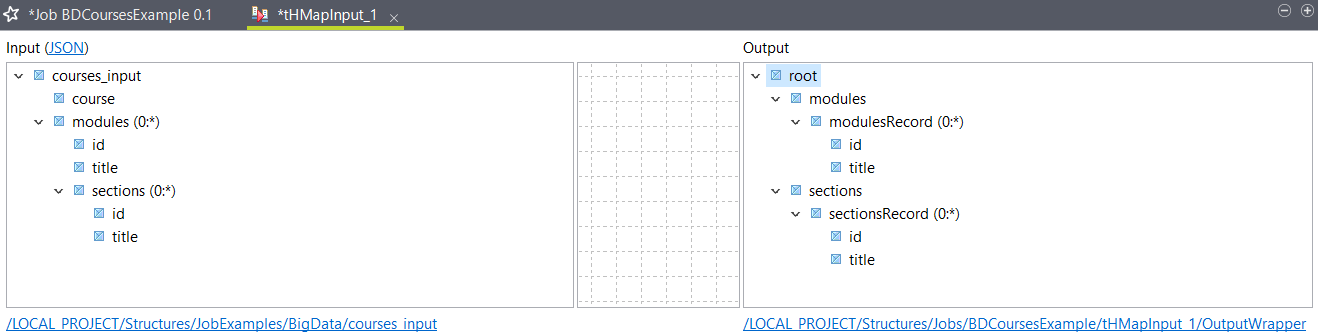
Résultats
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !