
Exporting a preparation made on an HDFS dataset
When you are finished preparing your dataset extracted from HDFS, you have the possibility to export it back directly to the cluster, or download it as a local file.
Note that the cluster where you will export your cleansed data, must be the same cluster from which you imported the data in the first place.
Procedure
-
Click the Export button in the application header
bar.
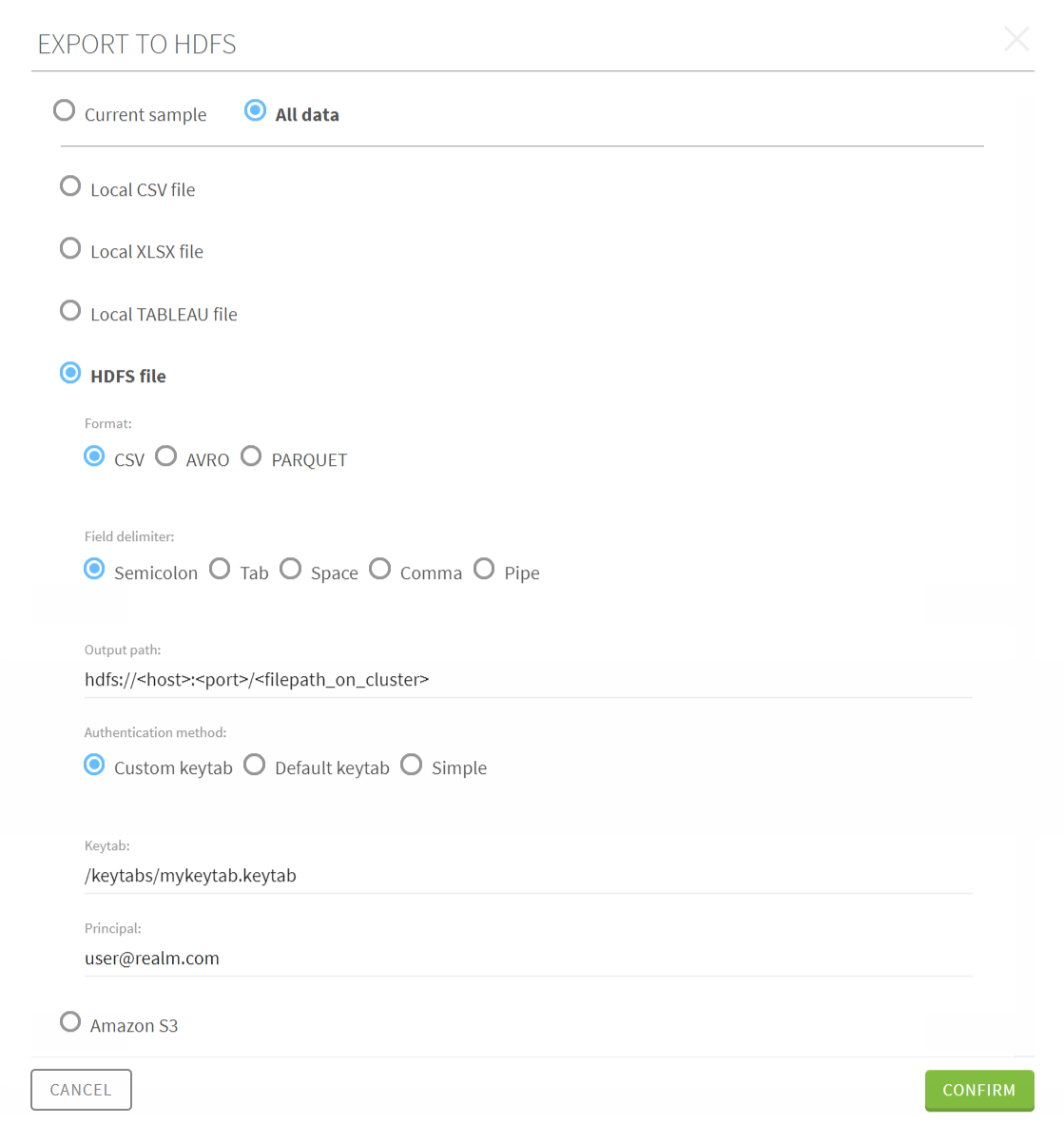
Results
If you chose to export your sample as a local file, your download of the output file directly starts.
In the case of a full export, whether it is as a local file or to the cluster, the export operation starts in the background. You can check the status of the export, and download your output file in the Export history page. For more information, see The export history page.
The whole operation is processed directly on the Hadoop cluster.
The export process triggers a refresh in the data that is fetched from the cluster, guaranteeing that the data displayed in the output is always up to date.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!