
Publier un message dans un topic Apache Pulsar
Ce scénario a pour objectif de vous aider à configurer et à utiliser des connecteurs dans un pipeline. Ce scénario doit être adapté en fonction de votre environnement et de votre cas d'utilisation.

Procédure
-
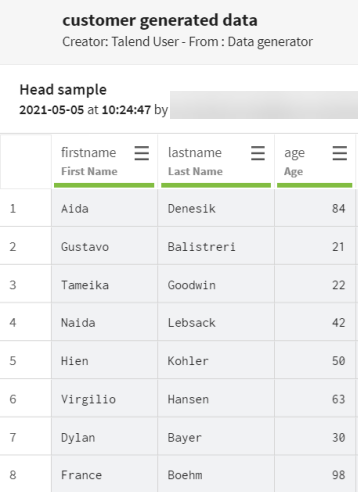
Renseignez les propriétés pour générer les données client·es de test de votre choix. Dans cet exemple:
- Dans le champ Rows (Lignes), saisissez 100 pour générer 100 enregistrements de test.
- Cliquez sur Add (Ajouter) , saisissez firstname dans le champ Name de l'élément, sélectionnez First Name dans la liste Type et saisissez 0 dans le champ Blank % (% vide) pour générer des prénoms aléatoires sans champ vide.
- Cliquez sur Add (Ajouter) , saisissez lastname dans le champ Name de l'élément, sélectionnez Last Name dans la liste Type et saisissez 0 dans le champ Blank % (% vide) pour générer des noms de famille aléatoires sans champ vide.
- Cliquez sur Add (Ajouter) , saisissez age dans le champ Name de l'élément, sélectionnez Age dans la liste Type. Saisissez 18 dans le champ Min et 99 dans le champ Max et saisissez 0 dans le champ Blank % (% vide), car vous souhaitez générer des âges compris entre 18 et 99, sans champ vide.
-
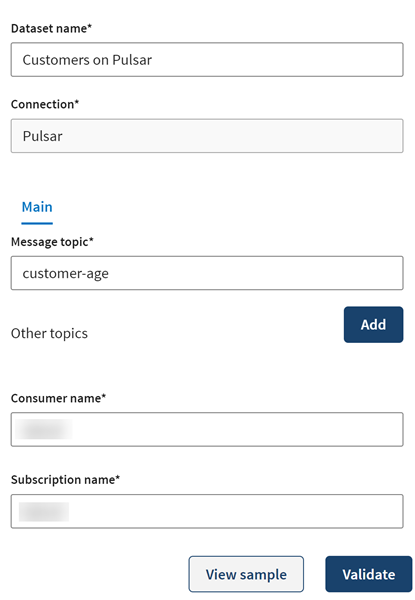
Dans le panneau Add a new dataset, nommez votre jeu de données. Dans cet exemple, le topic customer-age vide sera utilisé pour publier les données relatives aux informations clients traitées.
-
Cliquez sur
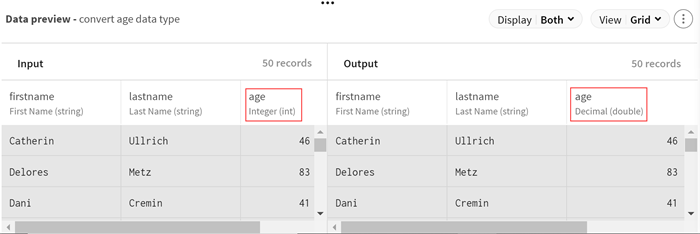
 et ajoutez un processeur Type converter au pipeline afin de modifier le type de données du champ age et de pouvoir effectuer des calculs sur les valeurs de champs. Le panneau de configuration s'ouvre.
et ajoutez un processeur Type converter au pipeline afin de modifier le type de données du champ age et de pouvoir effectuer des calculs sur les valeurs de champs. Le panneau de configuration s'ouvre.
-
(Facultatif) Consultez l'aperçu du processeur pour voir les données après la conversion du type.
-
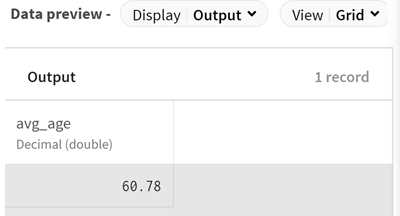
Cliquez sur et ajoutez un processeur Aggregate au pipeline afin de calculer l'âge moyen des clients. Le panneau de configuration s'ouvre.
-
(Facultatif) Consultez l'aperçu du processeur pour voir les données après l'opération d'agrégation.
-
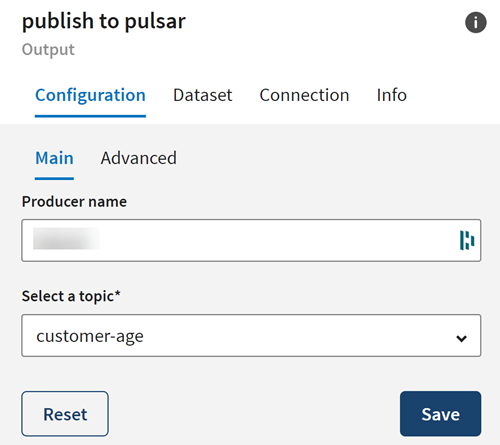
Dans l'onglet Configuration de la destination, consultez Producer name (Nom du producteur) et sélectionnez le topic dans lequel les données seront chargées.
Résultats
Votre pipeline est en cours d'exécution. Les données relatives à la moyenne d'âge de vos données locales ont été traitées et le flux de sortie est envoyé au topic Apache Pulsar défini.
Que faire ensuite
Une fois l'événement publié, vous pouvez consommer le message Pulsar dans un autre pipeline et l'utiliser comme jeu de données source :

Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !