
Concepts de Talend Cloud Pipeline Designer
Le diagramme et ces définitions vous permettent de comprendre les principaux concepts de Talend Cloud Pipeline Designer.
- Moteur distant Gen2 : Un Moteur distant Gen2 est un moteur d'exécution sécurisé sur lequel vous pouvez exécuter des pipelines en toute sécurité. Il vous permet d'avoir le contrôle sur votre environnement d'exécution et vos ressources, étant donné que vous pouvez créer et configurer le moteur dans votre propre environnement (Cloud privé virtuel ou on-premises).
Un Moteur distant Gen2 garantit :
-
que le traitement des données se fait dans un environnement sûr et sécurisé, car Talend n'a jamais accès aux données et ressources de vos pipelines,
-
des performances et une sécurité optimales en améliorant la localité des données au lieu de déplacer des volumes importants de données pour les calculs.
-
- Moteur Cloud pour le design :Le moteur Cloud est un runner built-in qui permet aux utilisateurs et utilisatrices de concevoir facilement des pipelines sans paramétrer de moteur de traitement. Avec ce moteur, vous pouvez exécuter deux pipelines en parallèle. Pour un traitement avancé des données, il est recommandé d'installer le Moteur distant Gen2 sécurisé.
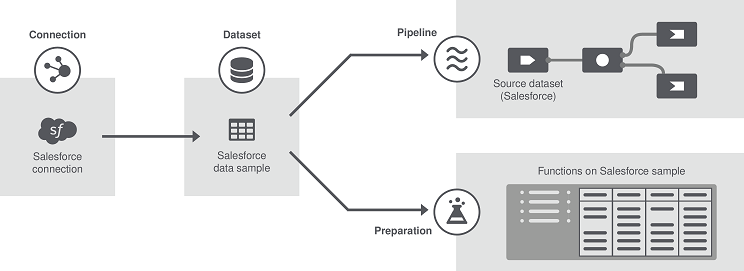
- Connection : les connexions sont des environnements ou des systèmes dans lesquels des jeux de données sont stockés, notamment de bases de données, systèmes de fichiers, systèmes ou des plateformes distribués. Les informations de connexion à ces systèmes doivent être configurées une seule fois, car elles sont réutilisables.
- Dataset (Jeu de données) : les jeux de données sont des collections de données. Ils peuvent être des tables de bases de données, des noms de fichiers, des topics (Kafka), des chemins de fichiers (HDFS), etc. Vous avez également la possibilité de créer des jeux de données de test que vous saisissez manuellement et stockez dans une connexion de test. Il est également possible d'importer des fichiers locaux comme jeux de données. Plusieurs jeux de données peuvent être connectés au même système (connectivité un-à-plusieurs) et sont stockés dans des connexions réutilisables.
- Pipeline : les pipelines sont composés d'un processus (comme un Job Talend) écoutant les données entrantes et d'un tuyau, le pipe, d'où proviennent les données d'une source, le jeu de données et sont envoyées vers une destination. Les pipelines peuvent être :
-
en mode batch (par lots) ou limités, ce qui signifie que les données sont collectées et que le pipeline s’arrête une fois que toutes les données sont traitées,
-
en mode streaming (flux) ou sans limite (unbounded), ce qui signifie que le pipeline ne s’arrête jamais de lire les données, sauf si vous l’arrêtez.
-
- Processor : les processeurs sont des composants que vous pouvez ajouter à vos pipelines afin de transformer vos données Batch ou Streaming entrantes et retourner les données transformées vers l'étape suivante de votre pipeline.
- Sample (Échantillon) : vos données seront visibles sous forme d'échantillon, récupéré des métadonnées du jeu de données.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !