
Configuring the Job for aggregating and filtering data in multiple SAP tables
Procedure
-
Click the tELTSAPMap component and then the
Component tab to open its Basic
settings view.
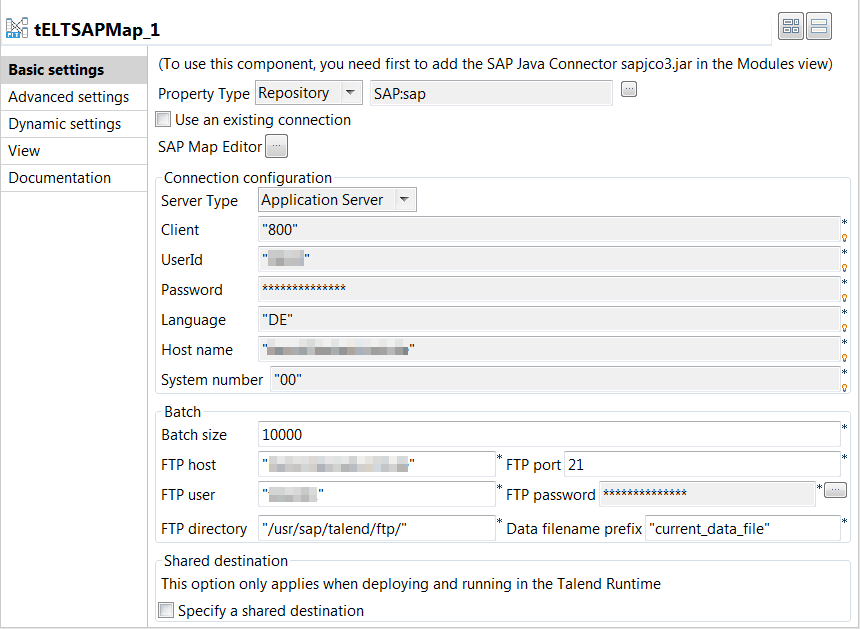
-
Click the [...] button next to SAP Map
Editor to open its map editor.
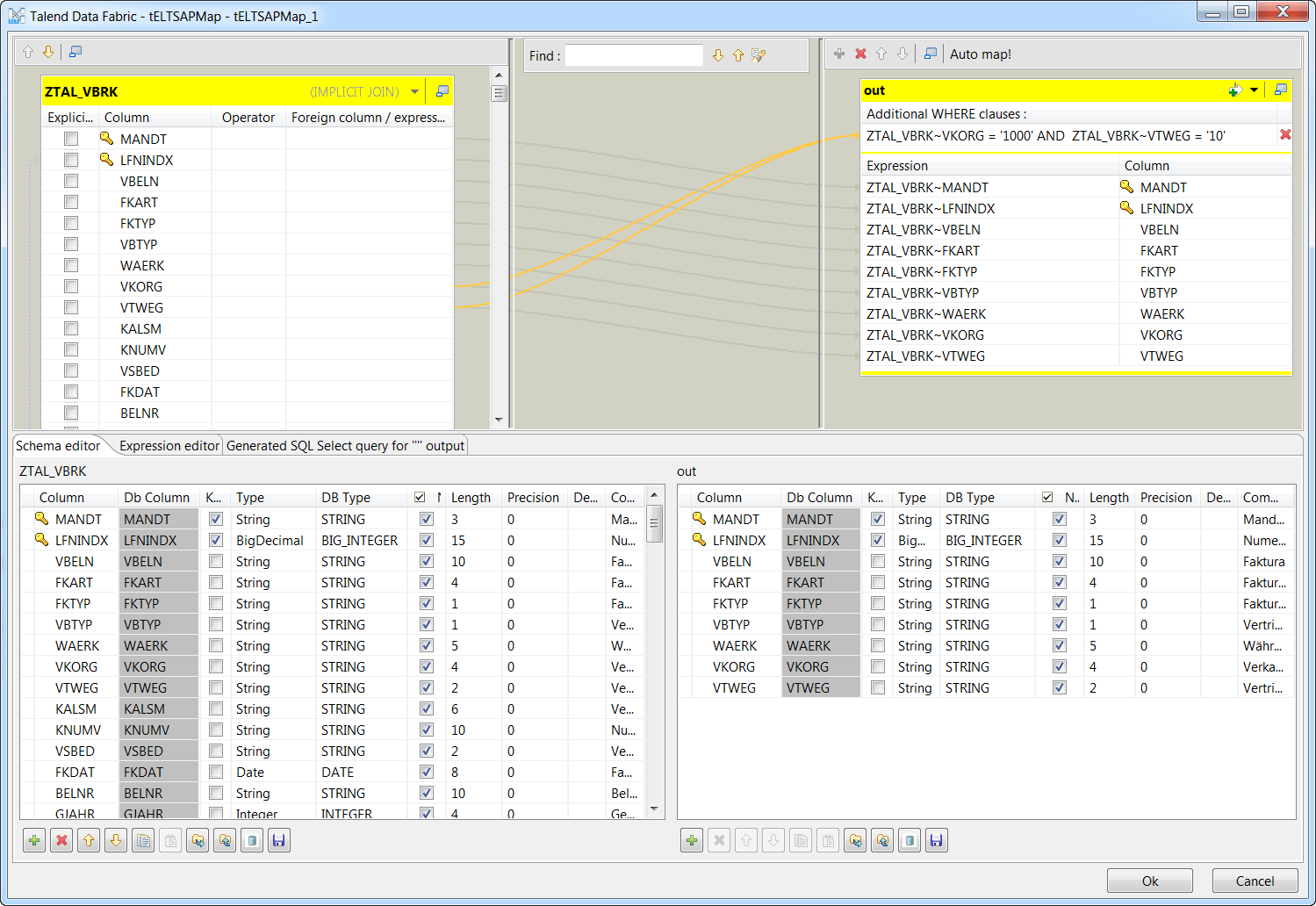
-
Click Generated SQL Select query for "" output at the
bottom and you will see the generated SQL SELECT query used to aggregate and
filter the data from the two tables.
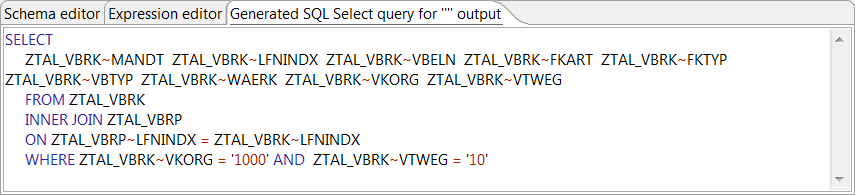
When done, click OK to close the map editor.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!