
Améliorer un modèle de rapprochement
Vous pouvez améliorer un modèle de rapprochement en modifiant les paramètres du composant tMatchModel.
Comme le résultat dépend de votre base de données, il n'y a pas de paramètre idéal. L'objectif des tests suivants est de montrer comment différentes configurations peuvent améliorer la qualité du modèle.
- le nom du site,
- son adresse et
- la source des données précédentes.
Les paramètres de référence sont :
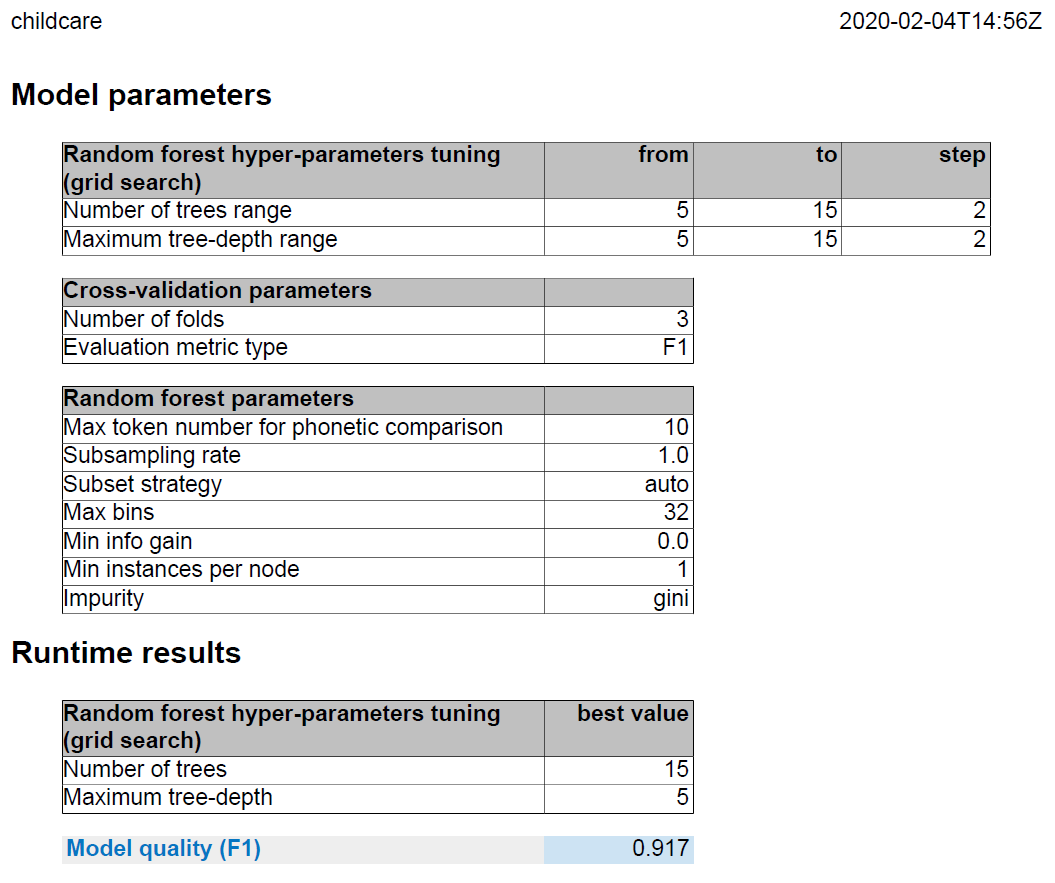
Pour effectuer ces tests, la méthode suivante est appliquée : les paramètres sont configurés différemment, un à la fois. Si la qualité du modèle est améliorée, le paramètre est conservé et un autre paramètre est configuré différemment. C'est une méthode permettant de constater l'impact des paramètres sur le modèle.
Seuls les paramètres sont modifiés. Comme testé dans Analyzing the heat map (uniquement en anglais), modifier la clé de rapprochement affecte la qualité du modèle. Address et Site name sont configurés comme clés de rapprochement.
Pour plus d'informations concernant les paramètres, consultez leur description dans la section Propriétés du tMatchModel (uniquement en anglais).
Après avoir exécuté plusieurs Jobs, la plus haute qualité du modèle est : 0.942.
| Paramètres | Paramètre de référence | Paramètres testés | Meilleure qualité du modèle avec un paramètre |
|---|---|---|---|
| Number of trees range 1 | de 5 à 15 |
5 à 20, 5 à 30, 5 à 50, 5 à 100 |
5 à 30, 5 à 50 ou 5 à 100 |
| Subsampling rate | 1.0 | 0.5 | 1.0 |
| Impurity | Gini | L'entropie | L'entropie |
| Max bins | 32 | 15 et 79 | 79 |
| Subset strategy | auto | Tous (auto, all, sqrt et log2) | auto |
| Min Instances per Node | 1 | 3 et 10 | 1 |
| 1 Plus l'intervalle des hyper-paramètres est grand (nombre et profondeur des arbres), plus la durée du Job est longue. | |||
Notez que le paramètre Evaluation metric type n'a pas été modifié. Il est resté configuré à F1. Comme le calcul est différent d'un type de métriques d'évaluation à un autre, modifier ce paramètre est inutile dans ces exemples.
Au cours des tests, aucun paramètre particulier n'a augmenté la qualité du modèle de 0.917 à 0.942, c'est la combinaison de ces paramètres qui en est la raison.
Les résultats précédents s'appliquent à une base de données spécifique. Selon votre base de données, la modification des paramètres comme ci-dessus n'aura pas le même impact. L'objectif est de vous montrer que, même si la qualité d'un modèle est satisfaisante, vous pouvez modifier les paramètres pour améliorer le modèle de rapprochement.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !