
Configurer les données dupliquées
Procédure
-
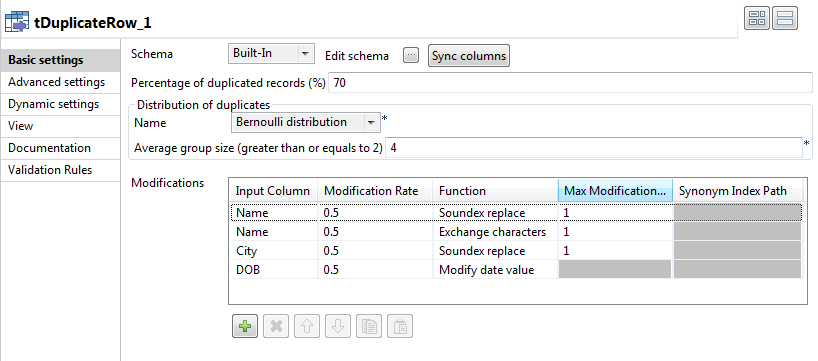
Double-cliquez sur le tDuplicateRow pour afficher sa vue Basic settings et définir ses propriétés.
-
Cliquez sur le bouton Edit schema afin d'afficher les colonnes d'entrée et de sortie et, si nécessaire, modifiez le schéma de sortie.
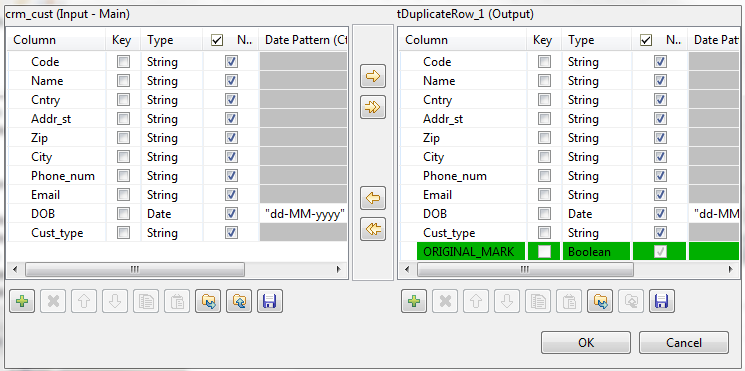 Le schéma de sortie de ce composant contient une colonne en lecture seule, ORIGINAL_MARK. Cette colonne indique, par true ou false, si l'enregistrement est un enregistrement original ou un doublon. Il y a un seul enregistrement original par groupe de doublons.
Le schéma de sortie de ce composant contient une colonne en lecture seule, ORIGINAL_MARK. Cette colonne indique, par true ou false, si l'enregistrement est un enregistrement original ou un doublon. Il y a un seul enregistrement original par groupe de doublons.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !