
Crawling de multiples jeux de données
Si vous devez importer un grand nombre de jeux de données d'une même source, au lieu de les créer un par un dans Talend Cloud Data Inventory, vous pouvez créer un crawler pour récupérer une liste complète de ressources en une opération.
Le crawling d'une connexion vous permet de récupérer des données à grande échelle et d'enrichir votre inventaire plus efficacement. Après avoir sélectionné une connexion, vous pourrez importer tout son contenu, ou une partie de son contenu, via une recherche et un filtre. Vous pourrez également sélectionner les utilisateur·trices ayant accès aux jeux de données créés.
- La sélection dynamique permet de récupérer toutes les tables correspondant à un filtre spécifique, quel que soit le contenu de la source de données, à tout moment.
- La sélection manuelle permet de sélectionner manuellement les tables à récupérer à partir de l'état actuel de votre source de données.
Le crawling d'une connexion pour plusieurs jeux de données est soumis aux prérequis et limitations suivant·es :
- Le rôle Dataset administrator (Administrateur des jeux de données) ou Dataset manager (Gestionnaire des jeux de données) vous a été attribué dans Talend Management Console, ou vous avez au moins le droit Crawling - Add (Crawling - Ajout).
- Vous utilisez une version 2022-02 ou supérieure du moteur distant.
- Vous ne pouvez crawler des données que d'une connexion JDBC. Un seul crawler peut être créé à la fois, à partir d'une connexion.
Procédure
-
Pour commencer à créer un crawler pour une connexion, vous pouvez :
- placer votre curseur sur votre connexion dans la liste des connexions, cliquer sur l'icône Crawl connection (Crawler la connexion) et cliquer sur le bouton Add crawler (Ajouter un crawler),
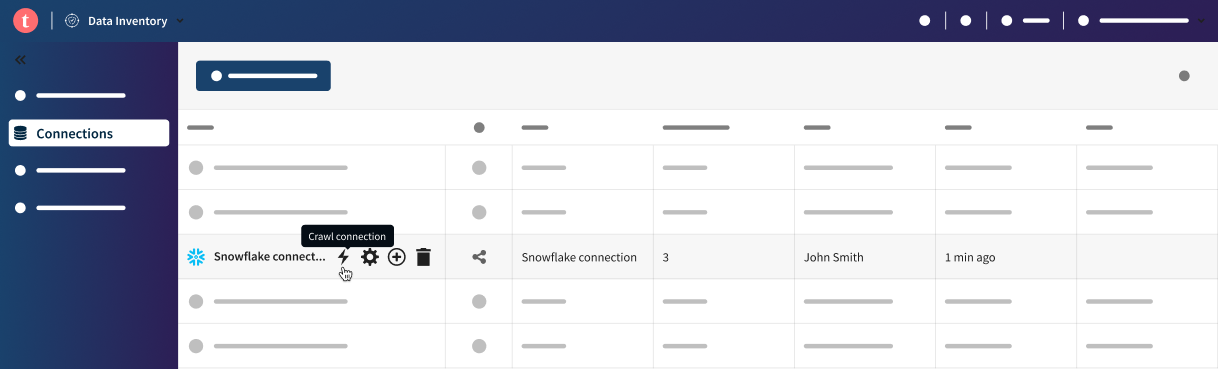
- ou cliquer sur votre connexion dans la liste des connexions et, dans l'onglet Crawler du panneau, cliquer sur Add crawler (Ajouter un crawler).
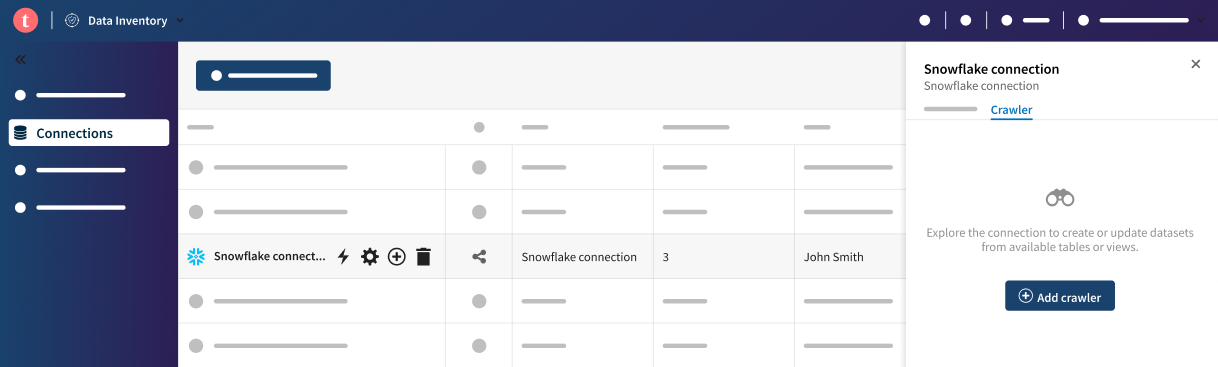
La fenêtre de configuration du crawler s'ouvre. - placer votre curseur sur votre connexion dans la liste des connexions, cliquer sur l'icône Crawl connection (Crawler la connexion) et cliquer sur le bouton Add crawler (Ajouter un crawler),
-
Cliquez sur Run.
Un processus asynchrone est lancé en tâche de fond, pour crawler les jeux de données sélectionnés, à partir de la connexion. Vous êtes à nouveau sur la liste des connexions, avec l'onglet Crawler ouvert dans le panneau de droite, dans lequel vous pouvez monitorer l'avancement de la création des jeux de données, ainsi que la disponibilité des échantillons.
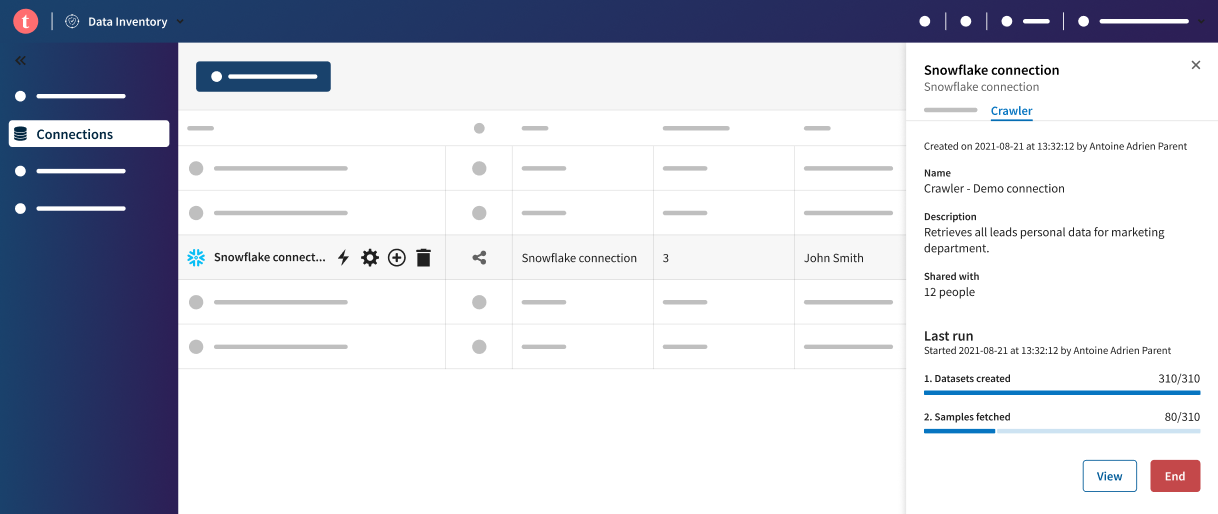 Note InformationsRemarque : Lorsque tous les échantillons ont été récupérés, la qualité de données et le Talend Trust Score™ de tous les jeux de données crawlés ont été calculés et sont visibles dans la liste des jeux de données, ainsi que dans la vue d'ensemble de chaque jeu de données. Si vous souhaitez commencer à travailler sur l'un des jeux de données crawlés avant que son échantillon soit disponible, vous pouvez en récupérer un manuellement, en cliquant sur Refresh sample (Actualiser l'échantillon) dans la vue de l'échantillon du jeu de données.
Note InformationsRemarque : Lorsque tous les échantillons ont été récupérés, la qualité de données et le Talend Trust Score™ de tous les jeux de données crawlés ont été calculés et sont visibles dans la liste des jeux de données, ainsi que dans la vue d'ensemble de chaque jeu de données. Si vous souhaitez commencer à travailler sur l'un des jeux de données crawlés avant que son échantillon soit disponible, vous pouvez en récupérer un manuellement, en cliquant sur Refresh sample (Actualiser l'échantillon) dans la vue de l'échantillon du jeu de données.
Résultats
Vous ne pouvez plus modifier la configuration d'un crawler une fois son exécution démarrée. Si le crawler est arrêté ou s'est terminé, vous pouvez modifier la sélection de tables, le nom et la description du crawler. Cependant, vous ne pouvez pas modifier les paramètres de partage. Pour crawler à nouveau la connexion, avec différents paramètres, supprimez le crawler et créez-en un nouveau.
Il est possible d'utiliser le nom d'un crawler comme facette dans une recherche de jeux de données, pour voir tous les jeux de données liés à un crawler donné.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !