
Dédupliquer des valeurs dans des colonnes
Vous pouvez utilisez la fonction Deduplicate rows with identical values pour facilement supprimer les lignes partiellement ou entièrement dupliquées avec d'autres lignes.
Les informations dupliquées sont souvent introduites dans les tableurs lors d'erreurs humaines, avec un mauvais copier-coller par exemple, ou lors d'opérations automatisées. Dans le jeu de données suivant, contenant des informations basiques sur des clients, vous remarquerez que les colonnes firstname et lastname contiennent toutes les deux des valeurs présentes plus d'une fois.
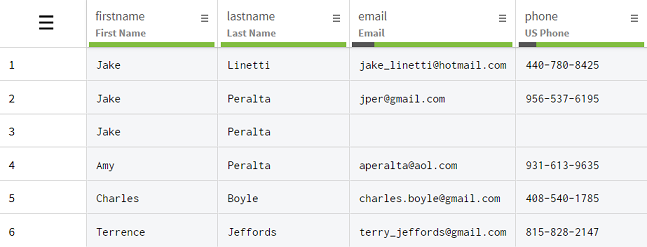
Jake et Peralta sont des entrées qui, lues séparément, laissent à penser que les colonnes firstname et lastname contiennent des doublons. Cependant, à y regarder de plus près, l'information des lignes 1, 2 et 4 provient de clients différents partageant le même nom ou prénom. La ligne 3 par contre est une vraie copie de la ligne 2, même s'il lui manque également des informations.
Une opération de déduplication sur les deux colonnes, séparément, résulterait en une perte d'informations précieuses sur les clients partageant le même nom ou prénom, vous utiliserez donc la fonction Deduplicate rows with identical values sur ces deux colonnes en même temps. De cette façon, cette fonction ne supprimera que les lignes avec des copies de noms et de prénoms, comme les lignes 2 et 3, mais également d'autres copies potentielles plus loin dans le jeu de données.
Procédure
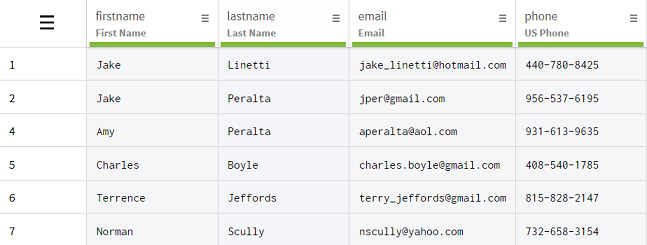
Résultats
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !