
Deduplizieren von Werten in Spalten
Sie können die Funktion Deduplicate rows with identical values (Zeilen mit identischen Werten deduplizieren) nutzen, um problemlos alle Zeilen zu löschen, die teilweise oder vollständig mit anderen Zeilen übereinstimmen.
Doppelte Informationen können in Kalkulationstabellen aufgrund eines menschlichen Fehlers, z. B. durch falsches Kopieren und Einfügen, oder automatisierter Vorgänge entstehen. Im folgenden Datensatz mit grundlegenden Kundendaten können Sie feststellen, dass die Spalten firstname (Vorname) und lastname (Nachname) Werte enthalten, die mehr als einmal vorkommen.
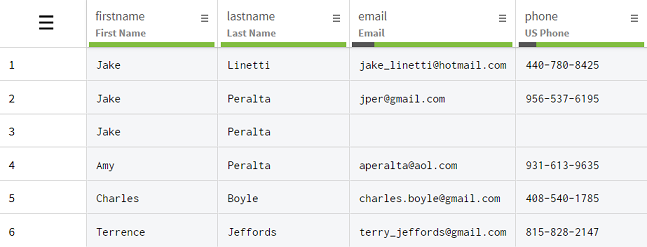
Jake und Peralta sind tatsächlich Einträge, die aussehen, als würden die Spalten firstname (Vorname) und lastname (Nachname) Duplikate enthalten, wenn man sie separat betrachtet. Bei näherer Betrachtung jedoch zeigt sich, dass die Informationen auf den Zeilen 1, 2 und 4 zu separaten Kunden gehören, die entweder denselben Vor- oder denselben Nachnamen haben. Zeile 3 hingegen ist ein wirkliches Duplikat von Zeile 2, außerdem fehlen einige Informationen.
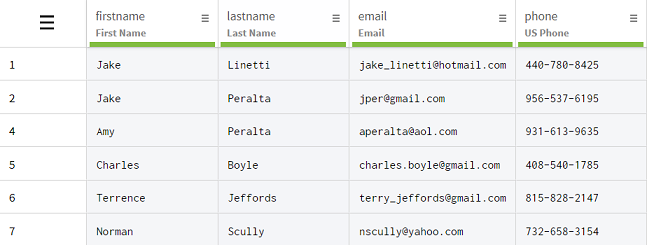
Das Sie bei einer für die zwei Spalten separat durchgeführten Deduplizierung wertvolle Informationen über Kunden verlieren würden, die zufällig denselben Vor- oder Nachnamen haben, wenden Sie die Funktion Deduplicate rows with identical values (Zeilen mit identischen Werten deduplizieren) auf beide Spalten gleichzeitig an. Auf diese Weise entfernt die Funktion nur Zeilen, in denen sowohl der Vor- als auch der Nachname Duplikate sind, wie in den Zeilen 2 und 3, aber auch andere potenzielle Duplikate weiter unten im Datensatz.
Prozedur
Ergebnisse
Hat diese Seite Ihnen geholfen?
Wenn Sie Probleme mit dieser Seite oder ihren Inhalten feststellen – einen Tippfehler, einen fehlenden Schritt oder einen technischen Fehler –, teilen Sie uns bitte mit, wie wir uns verbessern können!