
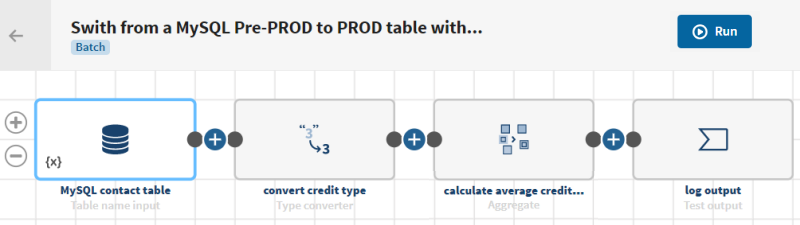
Utiliser des variables de contexte pour utiliser différentes chaînes de caractères de connexion lors de l'exécution
Dans ce scénario, des variables de contexte sont ajoutées pour écraser les identifiants de connexion et passer d'une base de données de pré-production à une base de données de production lors de l'exécution.
Avant de commencer
-
Vous avez précédemment créé une connexion au système stockant vos données source, ici une connexion MySQL.
-
Vous avez précédemment ajouté le jeu de données contenant vos données source.
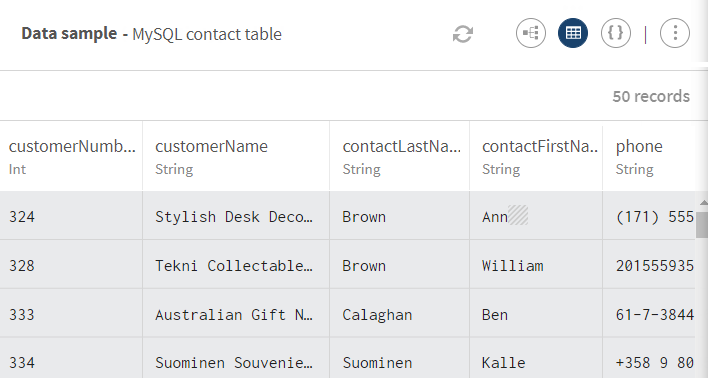
Ici, une table contenant des données de contact comprenant des identifiants clients, noms, adresses, pays, limites de crédit, etc.
- Vous avez également créé la connexion de destination, ici un jeu de données de test pour stocker les logs de sortie.
Procédure
-
Cliquez sur ADD SOURCE pour ouvrir le panneau vous permettant de sélectionner vos données source, ici MySQL contact table. Un échantillon de vos données est affiché dans le panneau de prévisualisation.
-
Cliquez sur le bouton
 et ajoutez un processeur Type converter au pipeline. Le panneau de Configuration s’affiche.
et ajoutez un processeur Type converter au pipeline. Le panneau de Configuration s’affiche.
-
Cliquez sur le bouton et ajoutez un processeur Aggregate au pipeline. Le panneau de Configuration s’affiche.
-
Cliquez sur Save (Sauvegarder) pour sauvegarder votre configuration.
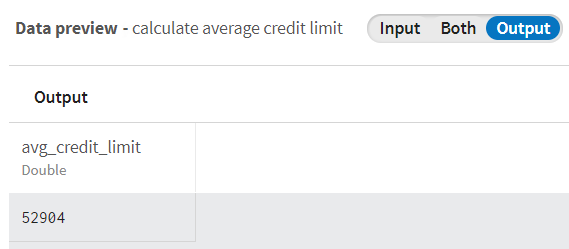
Vous pouvez voir que les enregistrements concernant les limites de crédit sont convertis en type Double.
-
(Facultatif) Si vous exécutez votre pipeline à cette étape, vous pouvez voir dans les logs :
- que le pipeline a bien été exécuté et que 52 enregistrements ont été lus,
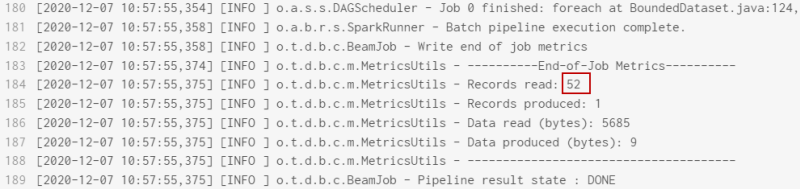
- qu'aucune variable de contexte n'a été configurée dans ce pipeline.

- que le pipeline a bien été exécuté et que 52 enregistrements ont été lus,
-
Retournez dans l'onglet Connection de la source MySQL contact table pour ajouter et attribuer une variable :
-
Cliquez sur l'icône
 près du paramètre JDBC URL (URL JDBC) pour ouvrir la fenêtre Add a variable (Ajouter une variable).
près du paramètre JDBC URL (URL JDBC) pour ouvrir la fenêtre Add a variable (Ajouter une variable).
-
Cliquez sur Save (Sauvegarder) pour sauvegarder votre configuration.
Une fois la variable attribuée, l'icône
 s'affiche pour indiquer qu'une variable a été configurée dans le pipeline.
s'affiche pour indiquer qu'une variable a été configurée dans le pipeline.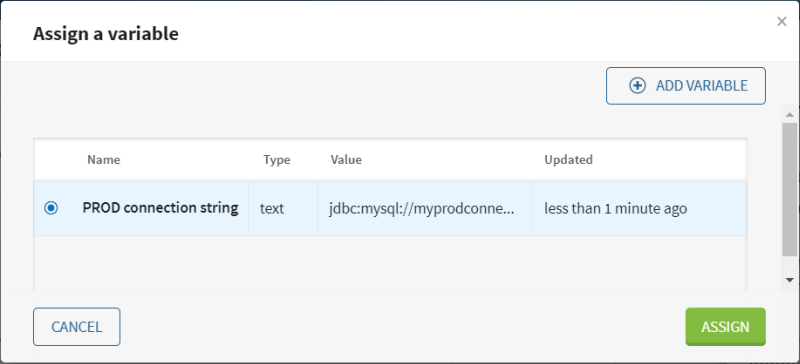
-
Cliquez sur l'icône
Résultats
- Dans les logs d'exécution du pipeline, vous pouvez voir que de nombreux enregistrements ont été lus (1153).
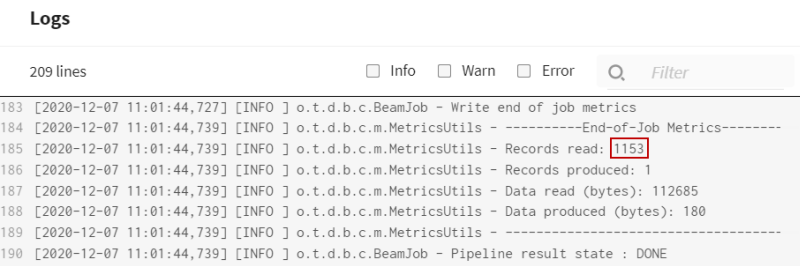
- Vous pouvez également voir la valeur de la variable de contexte utilisée pour récupérer les données de la table de production lors de l'exécution.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !