
デシジョンツリーモデルをトレーニング
このセクションでは、デシジョンツリーモデルのトレーニングを行う方法について説明します。
手順
-
残りの設定をデフォルト値のままにしておきます。
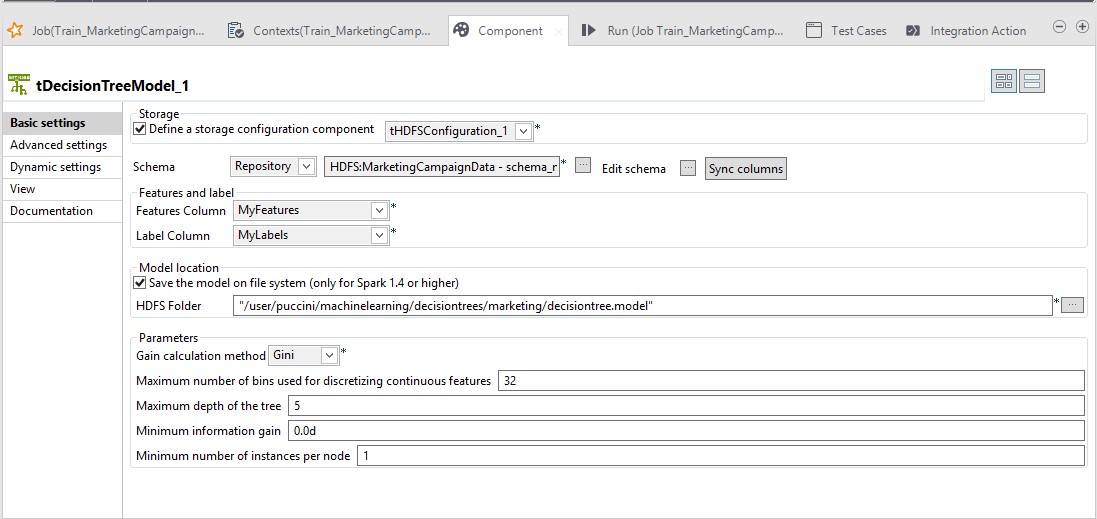
ジョブ設定は次のようになります。

-
[Use local mode] (ローカルモードを使用)チェックボックスを選択します。
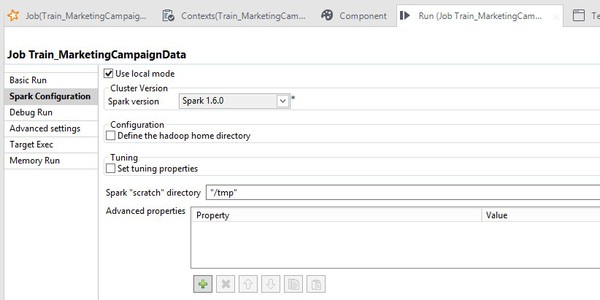 このジョブはHadoopクラスターで直接実行することもできます。これは本番環境で最も可能性が高いシナリオです。そのためには、[Use local mode] (ローカルモードを使用)チェックボックスを消去するなど、ジョブの実行方法を若干調整する必要があります。
このジョブはHadoopクラスターで直接実行することもできます。これは本番環境で最も可能性が高いシナリオです。そのためには、[Use local mode] (ローカルモードを使用)チェックボックスを消去するなど、ジョブの実行方法を若干調整する必要があります。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。