
Big Data
|
機能 |
説明 |
対象製品 |
|---|---|---|
| Spark BatchジョブでSparkデータセットのパーティションを管理する新コンポーネントtManagePartitionsを追加 | Spark Batchジョブで、現在非推奨となっているtPartitionに代わってtManagePartitionsという新しいコンポーネントを利用できるようになりました。このコンポーネントでは、入力データセットのパーティショニングを視覚的に定義することでパーティションを管理できます。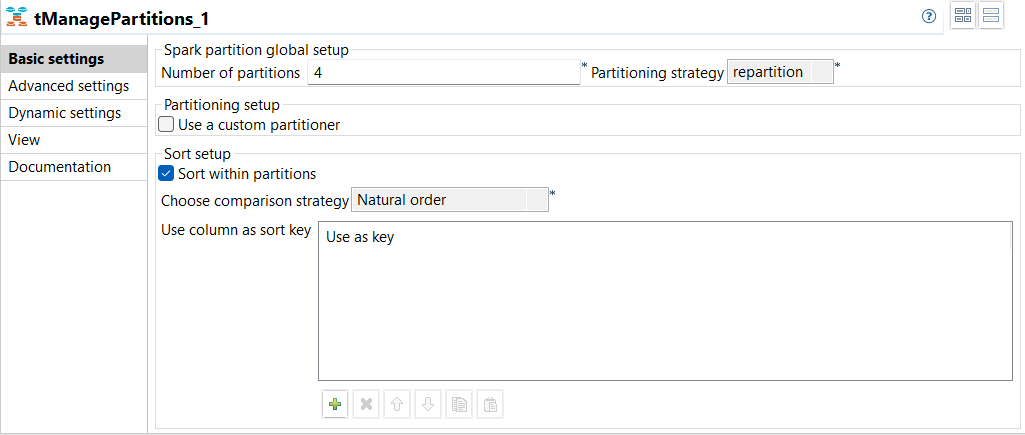
|
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
| Spark BatchジョブでtManagePartitionsを伴う自動パーティショニングをサポート | SparkジョブにあるtManagePartitionsの[Basic settings] (基本設定)ビューから[Partitioning strategy] (パーティショニング戦略)ドロップダウンリストで、[Auto] (自動)という新しいオプションが利用可能になりました。このオプションを使えば、データセットに適用する最適な戦略を計算できます。 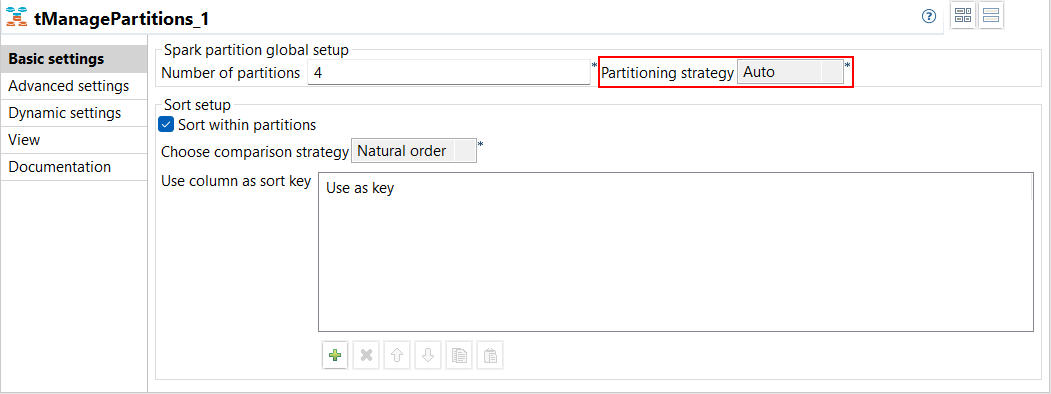
|
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
| Spark BatchジョブでSparkキャッシュをクリアする新コンポーネントtCacheClearを追加 | Spark BatchジョブでtCacheClearという新しいコンポーネントが利用可能になりました。このコンポーネントを使えば、tCacheOutによって保存されたRDD (Resilient Distributed Datasets)キャッシュをメモリから削除できます。 キャッシュのクリアはよい取り組みです。たとえばキャッシュレイヤーが満杯になった場合、SparkはLRU (Least Recently Used)戦略を使ってメモリからのデータ破棄を開始します。そのため、アンパーシストすることで、何を破棄させるべきかについてさらにコントロールし続けられるようになります。また、メモリに空き容量があればそれだけ、Sparkがハッシュマップのビルドなどの実行に充てることができます。 |
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
| 標準ジョブでtImpalaCreateTableを伴うKudu形式をサポート | 標準ジョブでtImpalaCreateTableを使ってテーブルを作成する時は、Kudu形式がサポートされます。Kudu テーブルで作業する場合は、[Kudu partition] (Kuduパーティション)という新しいパラメーターで作成するパーティションの数を設定することもできます。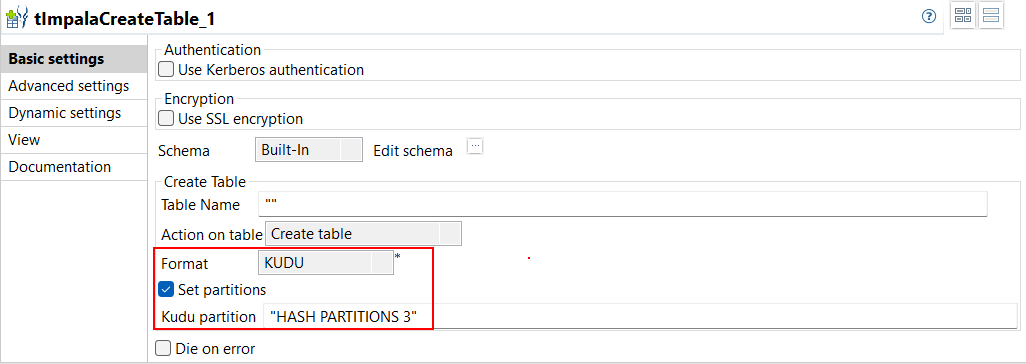
|
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
| 標準ジョブでHBaseテーブルから行を削除する新コンポーネントtHBaseDeleteRowを追加 | 標準ジョブでtHBaseDeleteRowという新しいコンポーネントが利用可能になりました。このコンポーネントでは、行キーを指定することで、HBaseテーブルからデータのある行を削除できます。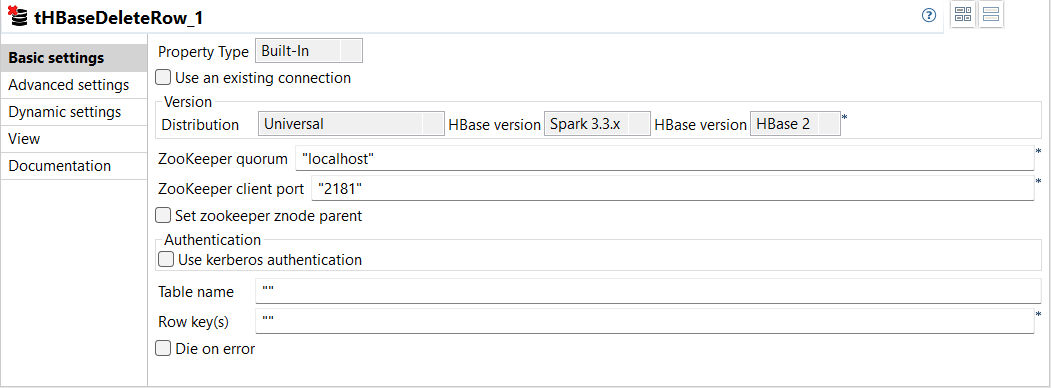
|
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
| CDP Public CloudでKnoxを使い、HBaseコンポーネントを伴うSpark Batchジョブを実行可能 | CDP Public Cloudで実行するSpark Batchジョブで、HBaseを伴うKnoxを使用できるようになりました。Knoxは、tHBaseConfigurationパラメーターかHBaseメタデータウィザードで設定できます。 |
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
| Spark BatchジョブでHBaseテーブルからの並列読み取りをサポート | Spark BatchジョブにあるtHBaseInputの[Basic settings] (基本設定)ビューで、[Partition by table regions] (テーブルリージョンごとにパーティショニング)という新しいオプションが利用可能になりました。このオプションは、HBaseテーブルのリージョン数を使ってデータを並列に読み取ることができます。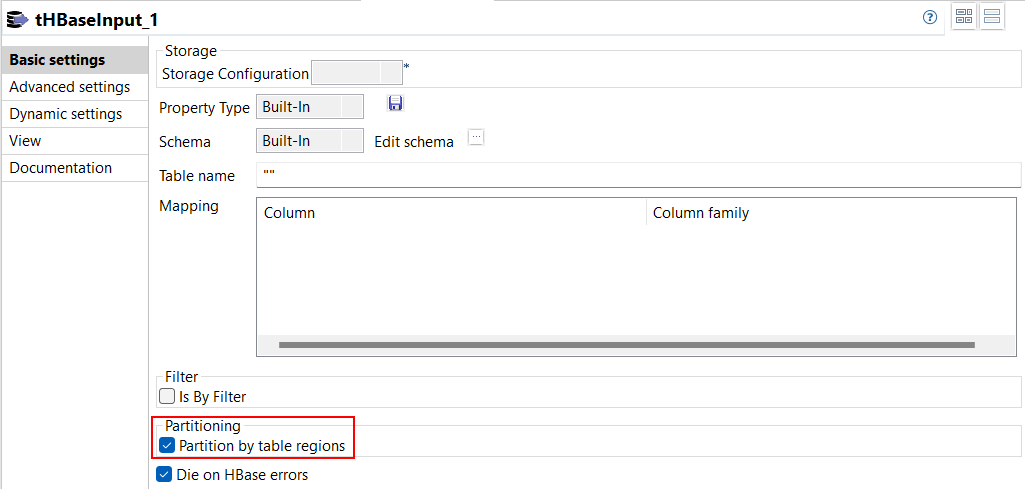
|
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。