
Apache Pulsarトピックにメッセージを公開
このシナリオは、パイプラインでコネクターを簡単にセットアップして使用できるようにすることを目的としています。お使いの環境とユースケースに適応させてください。

手順
-
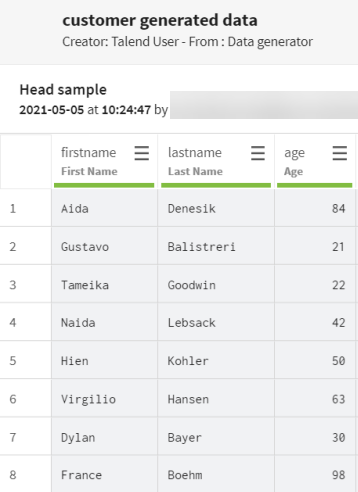
プロパティを入力して、目的のテスト顧客データを生成します。この例では、単純なLDAPプロトコルを使用しています。
- テストレコードを100件生成したいので、[Rows] (行)フィールドに100を入力します。
- [Add] (追加)フィールドをクリックし、エレメントの[Name] (名前)フィールドにfirstnameを入力し、[Type] (タイプ)リストで[First Name] (ファーストネーム)を選択して、空のフィールドを含まないランダムなファーストネームを生成したいので、[Blank %] (空白%)フィールド内に0を入力します。
- [Add] (追加)フィールドをクリックし、エレメントの[Name] (名前)フィールドにlastnameを入力し、[Type] (タイプ)リストで[Last Name] (ラストネーム)を選択して、空のフィールドを含まないランダムなラストネームを生成したいので、[Blank %] (空白%)フィールド内に0を入力します。
- [Add] (追加)フィールドをクリックし、エレメントの[Name] (名前)フィールドにageを入力し、[Type] (タイプ)リストで[Age] (年齢)を選択して、空のフィールドを含まない18歳から99歳の年齢を生成したいので、[Min] (最小)フィールドに18、[Max] (最大)フィールドに99、[Blank %] (空白%)フィールドに0を入力します。
-
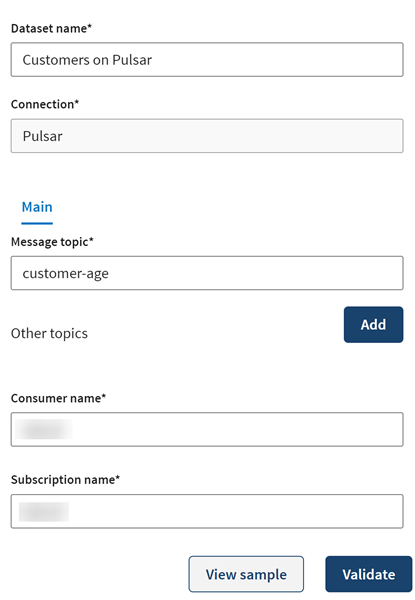
[Add a new dataset] (新しいデータセットを追加)パネルで、データセットに名前を付けます。この例では、今のところは空であるcustomer-ageトピックを使って処理済み顧客情報に関するデータを公開します。
-
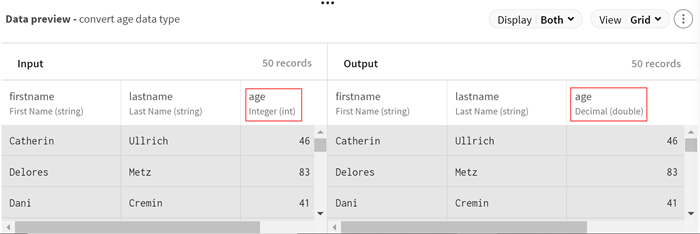
 をクリックし、Type converterプロセッサーをパイプラインに追加して、ageフィールドのデータ型を変更してフィールド値に計算を実行できるようにします。設定パネルが開きます。
をクリックし、Type converterプロセッサーをパイプラインに追加して、ageフィールドのデータ型を変更してフィールド値に計算を実行できるようにします。設定パネルが開きます。
-
オプションとして、プロセッサーのプレビューを表示し、タイプ変換後のデータを確認します。
-
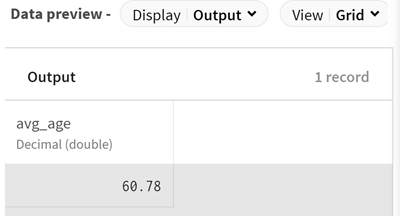
をクリックしてパイプラインにAggregateプロセッサーを追加し、顧客の平均年齢を計算できるようにします。設定パネルが開きます。
-
オプションとして、プロセッサーのプレビューを表示し、集計操作後のデータを確認します。
-
デスティネーションの[Configuration] (設定)タブで、[Producer name] (プロデューサー名)にチェックを入れ、データのロード先となるトピックを選択します。
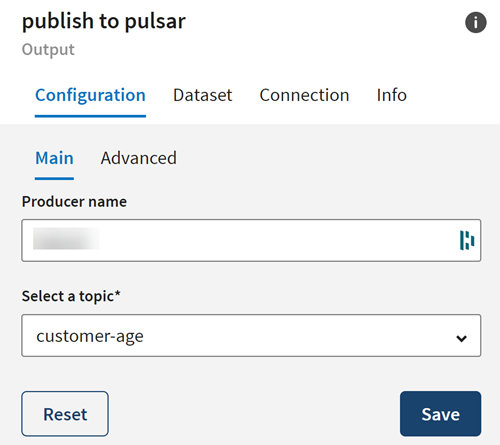
タスクの結果
パイプラインは実行中となり、ローカルデータからの平均年齢データが処理され、定義したApache Pulsarトピックに出力フローが送信されます。
次のタスク
イベントが公開された後は、別のパイプラインでPulsarメッセージを消費してソースデータセットとして使用できます。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。