
Créer un Job afin d'extraire des entités nommées à partir de données textuelles
Dans ce Job, le tNLPPredict prédit les entités nommées et libelle automatiquement les données textuelles divisées en termes individuels, à l'aide d'un modèle de classification.
Procédure
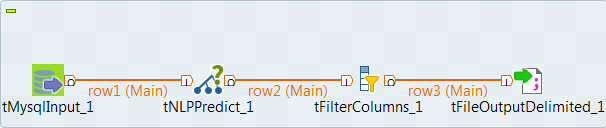
- Déposez les composants suivants de la Palette dans l'espace de modélisation graphique : un tMysqlInput, un tNLPPredict, un tFilterColumns et un tFileOutputDelimited.
- Reliez les composants à l'aide de liens .
Résultats
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !