
Extraire des entités nommées à partir de données textuelles
Dans ce Job, le tNLPPredict prédit les entités nommées et libelle automatiquement les données textuelles, à l'aide d'un modèle de classification généré par le tNLPModel.
Procédure
-
Double-cliquez sur le tNLPPredict pour afficher sa vue Basic settings et définissez les propriétés du composant.
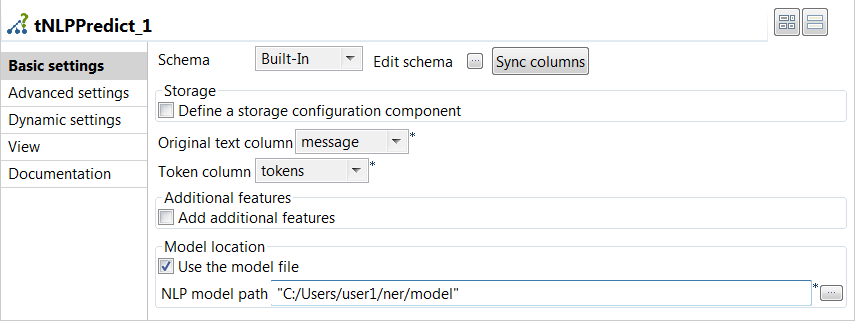
- Cliquez sur le bouton Sync columns afin de récupérer le schéma du composant précédent.
- Dans la liste Original text column, sélectionnez la colonne qui contient le texte à libeller, text dans cet exemple.
- Dans la liste Token column, sélectionnez la colonne utilisée pour la création des caractéristiques et la prédiction, tokens dans cet exemple.
- Dans la liste NLP Library, sélectionnez la même bibliothèque que celle utilisée pour générer le modèle de classification.
- Si le modèle de reconnaissance des entités nommées est stocké dans un seul fichier, cochez la case Use the model file.
- Saisissez le chemin d'accès au modèle de classification dans le champ NLP model path.
-
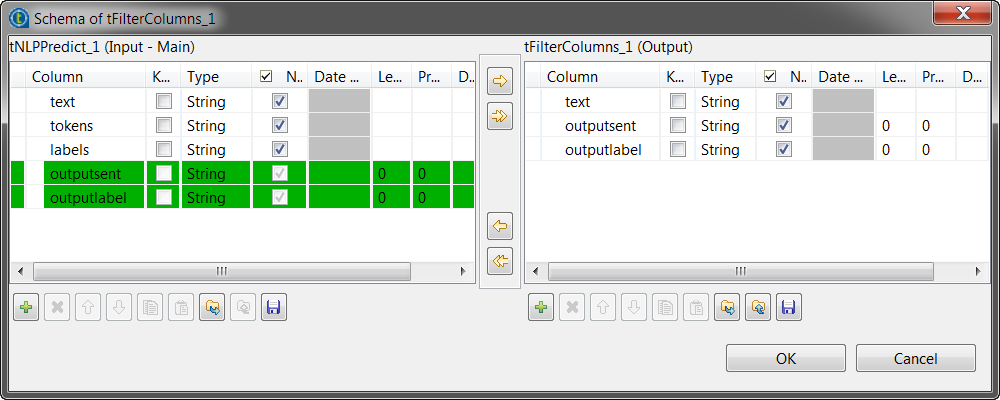
Double-cliquez sur le tFilterColumns pour afficher sa vue Basic settings et définissez ses propriétés.
-
Configurez le schéma en Built-In, puis cliquez sur Edit schema pour conserver uniquement les colonnes contenant le texte original, le texte libellé et les libellés.
-
Configurez le schéma en Built-In, puis cliquez sur Edit schema pour conserver uniquement les colonnes contenant le texte original, le texte libellé et les libellés.
-
Double-cliquez sur le tFileOutputDelimited pour afficher sa vue Basic settings et définissez ses propriétés.
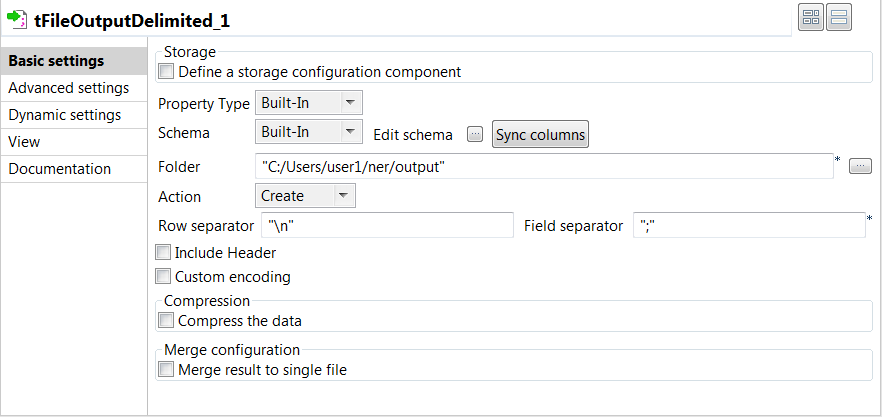
- Cliquez sur le bouton Sync columns afin de récupérer le schéma du composant précédent.
- Spécifiez le chemin d'accès au dossier de destination du texte libellé et des libellés dans le champ Folder.
- Saisissez "\n" dans le champ Row separator et ";" dans le champ Field separator.
Résultats
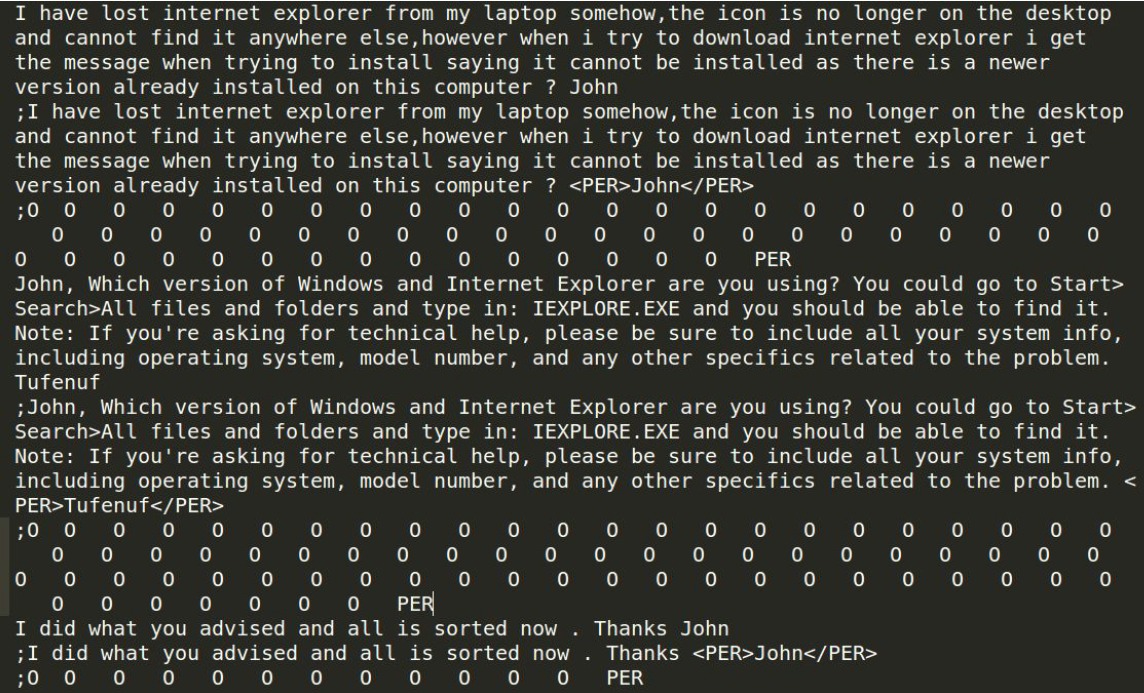
Les fichiers écrits en sortie contiennent le texte original, le texte libellé et les libellés. La tâche de reconnaissance d'entités nommées s'est déroulée correctement puisque les noms de personnes ont été extraits du texte original.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !