
Contextualisation des paramètres de connexion à Hadoop
Avant de commencer
-
Assurez-vous que la machine cliente sur laquelle est installé le Studio Talend peut reconnaître les noms d'hôtes des nœuds du cluster Hadoop à utiliser. Dans cet objectif, ajoutez les mappings des entrées adresse IP/nom d'hôte pour les services de ce cluster Hadoop dans le fichier hosts de la machine cliente.
Par exemple, si le nom d'hôte du serveur du NameNode Hadoop est talend-cdh550.weave.local, et son adresse IP est 192.168.x.x, l'entrée du mapping est la suivante : 192.168.x.x talend-cdh550.weave.local.
-
Le cluster Hadoop à utiliser a été correctement configuré et est en cours de fonctionnement.
-
Une connexion à Hadoop a été correctement définie en suivant les étapes présentées dans Définition de la connexion à Hadoop (uniquement en anglais).
-
La perspective Integration est active.
-
Cloudera est l'exemple de distribution de cet article. Si vous utilisez une distribution différente, vous devez garder à l'esprit les prérequis particuliers expliqués comme suit :
-
Si vous devez vous connecter à MapR à partir du Studio, assurez-vous d'avoir installé le client MapR sur la même machine que le Studio et d'avoir ajouté la bibliothèque client de MapR dans la variable PATH de cette machine. Selon la documentation MapR, la ou les bibliothèques d'un client MapR correspondante(s) à chaque version de système d'exploitation peut ou peuvent être trouvée(s) sous MAPR_INSTALL\/hadoop\hadoop-VERSION/lib/native. Par exemple, pour Windows, la bibliothèque est lib\MapRClient.dll dans le fichier Jar du client MapR. Pour plus d'informations, consultez la documentation MapR (uniquement en anglais) (en anglais).
-
Si vous devez vous connecter à un cluster Google Dataproc, définissez le chemin d'accès du fichier d'identifiants de Google associé au compte du service à utiliser afin que la fonctionnalité Check service de l'assistant de la métadonnée puisse vérifier votre configuration.
Pour plus d'informations concernant la définition de la variable d'environnement, consultez Getting Started with Authentication (uniquement en anglais) (en anglais) de la documentation Google.
-
Procédure
-
Saisissez un nom pour le groupe de contextes, par exemple smart_connection, puis cliquez sur Next.
Une vue en lecture seule de ce groupe de contextes est créée et renseignée automatiquement avec les paramètres d'une connexion à Hadoop donnée que vous avez définie dans Définition de la connexion à Hadoop (uniquement en anglais).

Vous pouvez également noter que tous les paramètres de connexion ne sont pas ajoutés au groupe de contextes, ce qui signifie qu'ils ne sont pas tous contextualisés, comme prévu.
-
Cliquez sur Finish pour passer à l'étape 2 de l'assistant de connexion Hadoop.
Les paramètres de connexion ont été automatiquement définis pour utiliser des variables de contexte et rester en lecture seule.

-
Cliquez sur OK afin de valider les modifications et fermer l'assistant New context. Le nouveau contexte est ajouté dans liste de contexte.

-
Définissez le nouveau contexte pour contenir les valeurs des paramètres de connexion pour un cluster Hadoop différent, par exemple votre cluster de production.

-
La connexion à Hadoop est contextualisée et vous pouvez continuer à créer des connexions enfants pour ses éléments comme HBase, HDFS et Hive etc. basées sur cette connexion. Chaque assistant de connexion contient le bouton Export as context. Utilisez-le pour contextualiser chacune de ces connexions.

Résultats
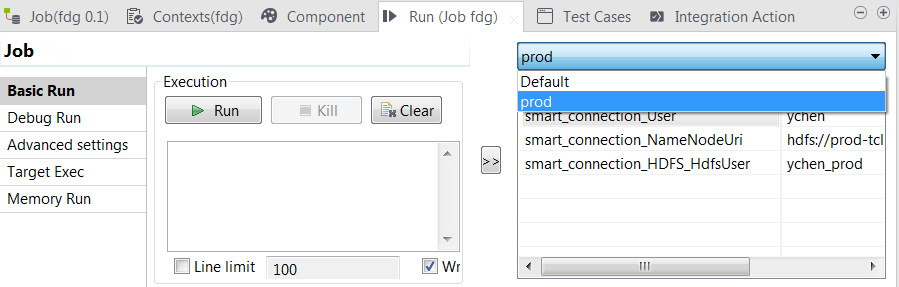
Lorsque vous réutilisez ces connexions via la liste Property type dans un composant donné dans vos Jobs, ces contextes sont listés dans la vue Run du Job.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !