
Deduplizieren von Zeilen
Mit der Funktion Remove duplicate rows (Zeilenduplikate entfernen) können Sie problemlos alle Zeilen löschen, die vollständig identisch mit anderen Zeilen sind, und von diesen nur jeweils eine Instanz im Datensatz beibehalten.
Doppelte Informationen können in Kalkulationstabellen aufgrund eines menschlichen Fehlers, z. B. durch falsches Kopieren und Einfügen, oder automatisierter Vorgänge entstehen. In diesem Beispiel haben Sie einen Datensatz mit Kundendaten erhalten, in dem alle Zeilen systematisch verdoppelt wurden.
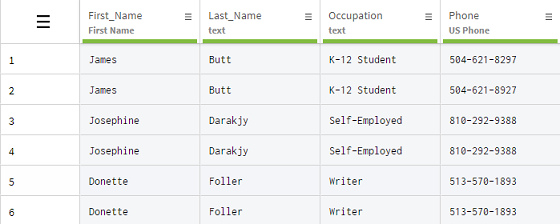
Sie ziehen die Funktion Remove duplicate rows (Zeilenduplikate entfernen) heran, um Ihren Datensatz ganz einfach zu bereinigen.
Prozedur
-
Positionieren Sie den Mauszeiger auf der Funktion Remove duplicate rows (Zeilenduplikate entfernen) und klicken Sie auf das Auge-Symbol, um eine Vorschau der Auswirkungen der Funktion anzuzeigen.
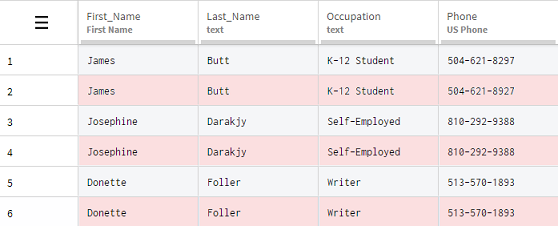
Ergebnisse
Alle Informationsduplikate werden durch eine einfache Aktion entfernt, sodass Ihr Datensatz nur noch eine gültige Instanz jeder Zeile enthält.
Hat diese Seite Ihnen geholfen?
Wenn Sie Probleme mit dieser Seite oder ihren Inhalten feststellen – einen Tippfehler, einen fehlenden Schritt oder einen technischen Fehler –, teilen Sie uns bitte mit, wie wir uns verbessern können!