
Anwendungsfall: Erstellen einer Pipeline zur Verarbeitung von Finanzdaten
Vorgehensweise zur Erstellung einer Pipeline, die hierarchische Finanzdaten anreichert und filtert (IBAN, Konto- und Transaktionsdaten usw.) und anschließend den Gesamtbetrag aller durchgeführten Transaktionen aggregiert und zählt.
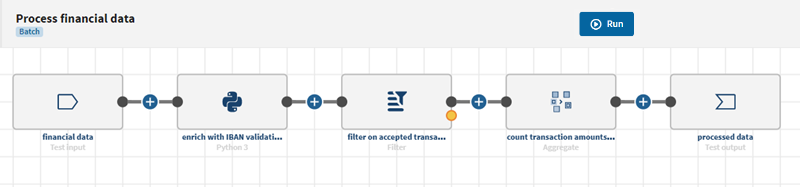
Prozedur
-
Klicken Sie in der oberen Symbolleiste auf das Stiftsymbol
 neben dem Pipeline-Standardnamen und geben Sie einen aussagekräftigen Namen für Ihre Pipeline ein.
neben dem Pipeline-Standardnamen und geben Sie einen aussagekräftigen Namen für Ihre Pipeline ein.
Example
Process financial data (Finanzdaten verarbeiten) -
Klicken Sie auf
 und fügen Sie einen Prozessor vom Typ Python 3 zur Pipeline hinzu. Dieser Prozessor ermöglicht die Kopie des Python-Codes, der die Eingabedaten verarbeitet und anreichert.
und fügen Sie einen Prozessor vom Typ Python 3 zur Pipeline hinzu. Dieser Prozessor ermöglicht die Kopie des Python-Codes, der die Eingabedaten verarbeitet und anreichert.
-
Klicken Sie auf Save (Speichern), um die Konfiguration zu speichern.
Die Eingabedaten werden entsprechend verarbeitet, und Sie können eine Vorschau der Änderungen anzeigen. Das neue Feld iban_valid wird in allen Datensätzen hinzugefügt.
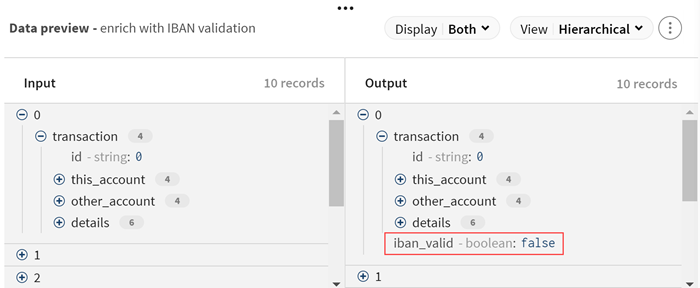
-
Klicken Sie auf und fügen Sie einen Prozessor vom Typ Filter zur Pipeline hinzu. Dieser Prozessor ermöglicht die Isolierung angenommener Transaktionen (gekennzeichnet durch das Tag AC, im Gegensatz zu abgelehnten Transaktionen mit dem Tag DC).
-
Führen Sie im Bereich Filters (Filter) Folgendes durch:
Die Eingabedaten werden entsprechend verarbeitet, und Sie können eine Vorschau der Änderungen anzeigen. Nur Datensätze mit angenommenen Transaktionen (AC) werden in der Ausgabe beibehalten.
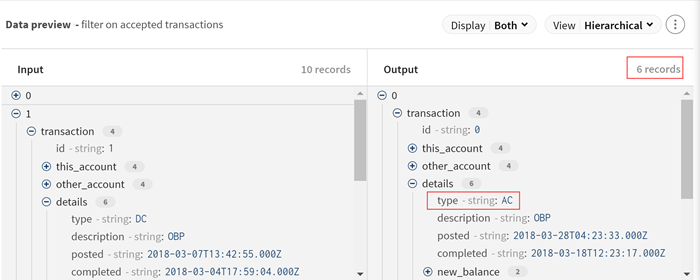
-
Klicken Sie auf und fügen Sie einen Prozessor vom Typ Aggregate (Aggregieren) zur Pipeline hinzu. Dieser Prozessor ermöglicht die Gruppierung von Transaktionen und die Berechnung des Gesamtbetrags dieser Transaktionen.
-
Fügen Sie im Bereich Operations (Operationen) eine Aggregationsfunktion hinzu:
- Wählen Sie .transaction.details.value.amount in der Liste Field path (Feldpfad) und Sum (Summe) in der Liste Operation aus.
- Legen Sie für das generierte Feld einen Namen fest, beispielsweise total_amount (Gesamtbetrag).
- Klicken Sie auf Save (Speichern), um die Konfiguration zu speichern.
Die Eingabedaten werden entsprechend verarbeitet, und Sie können nach der Filter- und Gruppierungsoperation eine Vorschau der berechneten Daten anzeigen. Mit einer gültigen IBAN-Nummer können 252, mit einen ungültigen IBAN-Nummer 81 Transaktionen durchgeführt werden.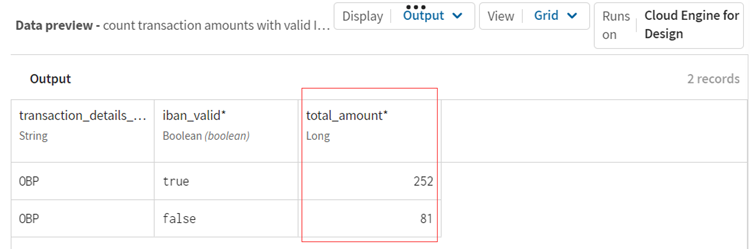
Hat diese Seite Ihnen geholfen?
Wenn Sie Probleme mit dieser Seite oder ihren Inhalten feststellen – einen Tippfehler, einen fehlenden Schritt oder einen technischen Fehler –, teilen Sie uns bitte mit, wie wir uns verbessern können!