
Schreiben von Daten in ein cloudbasiertes Data Warehouse (Snowflake)
Vorbereitungen
-
Sie haben die Datei financial_transactions.avro heruntergeladen und sie in Ihr Amazon S3-Bucket hochgeladen.
- Sie haben die unter Schreiben von Daten in einen Cloud-Speicher (S3) beschriebene Pipeline reproduziert und dupliziert und arbeiten jetzt mit dieser duplizierten Pipeline.
- Sie haben eine Moteur distant Gen2 sowie das zugehörige Ausführungsprofil über Talend Management Console erstellt.
In Talend Management Console sind standardmäßig die Moteur Cloud pour le design und ein entsprechendes Ausführungsprofil integriert. Dadurch können die Benutzer in kürzester Zeit ihre Arbeit mit der Anwendung aufnehmen. Es wird jedoch empfohlen, die sichere Moteur distant Gen2 zu installieren, die eine erweiterte Datenverarbeitung ermöglicht.
Prozedur
-
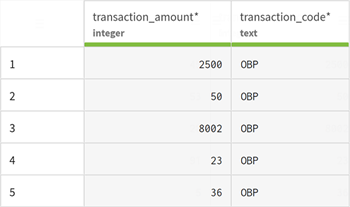
Klicken Sie auf View sample (Sample anzeigen), um zu prüfen, ob die Daten gültig sind und in der Vorschau angezeigt werden können.
-
Klicken Sie auf Validate (Validieren), um den Datensatz zu speichern. Der neue Datensatz wird der Liste auf der Seite Datasets (Datensätze) hinzugefügt und kann jetzt in Ihrer Pipeline als Zieldatensatz verwendet werden.
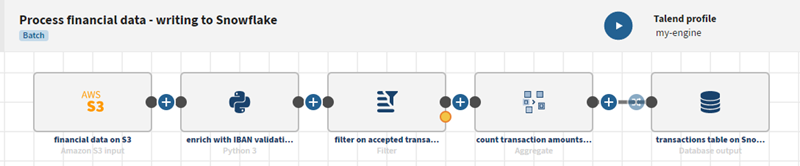
Das Symbol „Datenmapping“ neben dem Ziel wird vorübergehend deaktiviert, da es sich bei dem Eingabeschema nicht um ein flaches Schema handelt.
-
Klicken Sie auf das Symbol
 und fügen Sie nach dem Prozessor vom Typ Aggregate (Aggregieren) einen Prozessor vom Typ Field selector (Feldauswahl) hinzu, um die Felder auszuwählen, die Sie beibehalten möchten, und um das Schema abzuflachen. Daraufhin wird das Konfigurationsfenster geöffnet.
und fügen Sie nach dem Prozessor vom Typ Aggregate (Aggregieren) einen Prozessor vom Typ Field selector (Feldauswahl) hinzu, um die Felder auszuwählen, die Sie beibehalten möchten, und um das Schema abzuflachen. Daraufhin wird das Konfigurationsfenster geöffnet.
-
Klicken Sie im Auswahlmodus Simple (Einfach) auf
 , um das Fenster Select fields (Felder auswählen) zu öffnen:
, um das Fenster Select fields (Felder auswählen) zu öffnen:
- Wählen Sie die Felder aus, die beibehalten und abgeflacht werden sollen: description (Beschreibung) und total_amount (Gesamtbetrag).
- Klicken Sie auf Edit (Bearbeiten), um das Fenster wieder zu schließen.
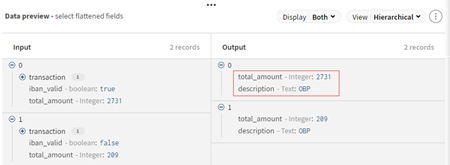
- Klicken Sie auf Save (Speichern), um die Konfiguration zu speichern und eine Vorschau der abgeflachten Felder anzuzeigen.
-
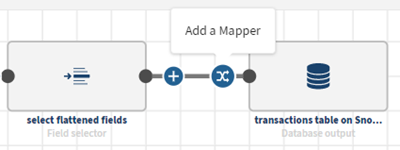
Sie verfügen jetzt über ein flaches Eingabeschema. Somit wird das Symbol
 aktiviert, d. h. Sie können einen Prozessor vom Typ Data mapping (Datenmapping) zur Pipeline hinzufügen. Daraufhin wird das Konfigurationsfenster geöffnet.
aktiviert, d. h. Sie können einen Prozessor vom Typ Data mapping (Datenmapping) zur Pipeline hinzufügen. Daraufhin wird das Konfigurationsfenster geöffnet.
-
Klicken Sie auf der Registerkarte Configuration (Konfiguration) auf Open mapping (Mapping öffnen), um den Datenmapping-Prozessor zu öffnen.
Einige der Eingabefelder werden automatisch einem auf ihrem Namen basierenden Ausgabefeld zugeordnet. Sie können diese Felder prüfen und dann das Mapping für das restliche Schema durchführen:
- Ordnen Sie das Eingabefeld total_amount (Gesamtbetrag) dem Ausgabefeld transaction_amount (Transaktion_Betrag) zu.
- Ordnen Sie das Eingabefeld description (Beschreibung) dem Ausgabefeld transaction_code (Transaktion_Code) zu.
- Klicken Sie auf Validate (Validieren), um das Mapping zu bestätigen.
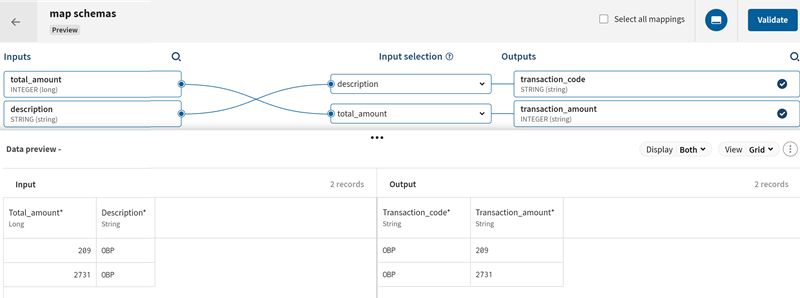
Der Inhalt des Eingabefelds total_amount (Gesamtbetrag) wird gemäß der für die Datenbank ausgewählten Operation (Einfügen, Aktualisieren, Upsert, Löschen) zum Inhalt des Ausgabefelds transaction_amount (Transaktion_Betrag) hinzugefügt.
Der Inhalt des Eingabefelds description (Beschreibung) wird zum Inhalt des Ausgabefelds transaction_code (Transaktion_Code) hinzugefügt.
Sie können das Ergebnis des Mappings im Bereich Data preview (Datenvorschau) überprüfen.
-
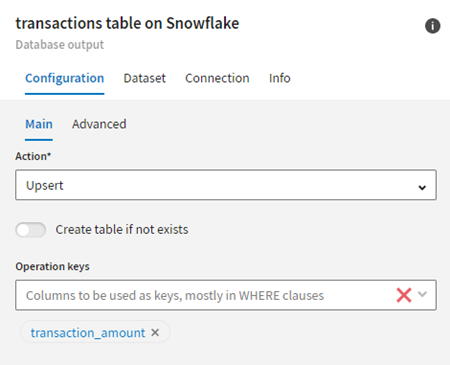
Wählen Sie vor der Ausführung der Pipeline Upsert auf der Konfigurationsregisterkarte des Snowflake-Datensatzes aus, um die Snowflake-Tabelle zu aktualisieren und die neuen Daten einzufügen. Legen Sie das Feld transaction_amount (Transaktion_Betrag) als Operationsschlüssel fest.
Ergebnisse
Sobald die Pipeline ausgeführt wird, werden die aktualisierten Daten in der Snowflake-Datenbanktabelle angezeigt.
Hat diese Seite Ihnen geholfen?
Wenn Sie Probleme mit dieser Seite oder ihren Inhalten feststellen – einen Tippfehler, einen fehlenden Schritt oder einen technischen Fehler –, teilen Sie uns bitte mit, wie wir uns verbessern können!