
Créer un pipeline
Créer un pipeline à partir de zéro.
Procédure
-
Cliquez sur l'icône
 afin de sélectionner un ou plusieurs composant·s de traitement selon vos besoins : filtrage, nettoyage, agrégation...
Dans le panneau [Add a processor], vous pouvez soit sélectionner un processeur dans la liste principale, soit saisir son nom ou sa description dans la zone de texte.
afin de sélectionner un ou plusieurs composant·s de traitement selon vos besoins : filtrage, nettoyage, agrégation...
Dans le panneau [Add a processor], vous pouvez soit sélectionner un processeur dans la liste principale, soit saisir son nom ou sa description dans la zone de texte. -
Sélectionnez le jeu de données de destination :
- Si vous avez déjà créé un jeu de données, sélectionnez-le dans la liste du panneau [Select a destination (Sélectionner une destination)] et cliquez sur Select (Sélectionner).
- Si vous n'avez pas créé de jeu de données, ajoutez-en un en cliquant sur Add dataset (Ajouter un jeu de données comme décrit dans Créer un jeu de données.
Exemple de pipeline consommant des données provenant d'une entrée S3, traitant et filtrant ces données, afin d'envoyer les données sélectionnées à une autre destination S3.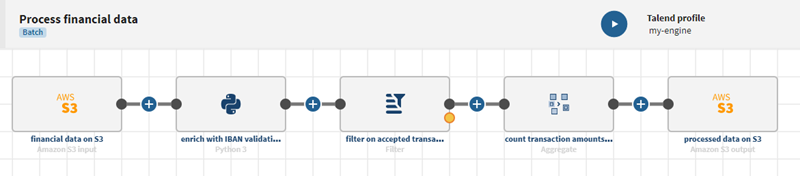
Notez que, avant d'exécuter votre pipeline, vous pouvez voir un aperçu de vos données à chaque étape du processus de conception.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !