
Data vs. Metadata-detected data classification
Of special importance are personally identifiable information, or Personally Identifiable Information (PII). Automation and completeness of the identification and classification of the PII objects in the data is fundamental to these activities. In many cases, data classes may be used to profile and match the criteria by which PII may be isolated. In this case, it is the actual data that is analyzed and used to classify the data element. This feature is referred to as data-detected data classification. Data-detected data classification is good at detecting common data patterns automatically but less focused on providing definitions
Some PII harvested objects, like Maiden Name and Date of Birth do not have unique data patterns and cannot be discovered using the data-detected data classification. Talend Data Catalog helps you to identify these types of harvested objects using the metadata-detected classification. This feature is referred to as metadata-detected type data classification. Metadata-detected data classification is good at providing authoritative and common definitions. It is more flexible but less precise than data-detected data classification.
A harvested object can have multiple metadata-detected data classifications (relationships with business terms). It can have one definition (data-detected) classification and many other semantic (metadata-detected) classifications. I.e., you may classify with the same business term several harvested objects that have different data types and patterns.
A harvested object can have multiple proposed, approved and assigned data classifications (tagged with data classes). Talend Data Catalog encourages users to be as precise as possible with the data classifications and strive for a harvested object to have one approved or assigned data classification.
In addition, in terms of semantic lineage, Talend Data Catalog uses data and metadata-detected data classifications to implement lookups of the inferred definition and related elements.
Metadata-detected data classification occurs automatically as you create or edit those data classes or when metadata is harvested. In addition, you may invoke the metadata-detected data classification explicitly. For data-detected data classification, you may manage it and invoke it by following the steps below.
Please see further details at:
Steps
- Add and edit a data class as needed.
- Browse for a glossary term to associate with the data class as necessary.
- For the source metadate, be sure to harvest the metadata with data profiling information captured.
- Invoke the automatic data classification either as a part of the harvest or using the Classify Data options.
- Navigate to the object page for the object you wish to work with.
You may also review and editing data class assignments in grid mode. However, they cannot be assigned in bulk.
- Talend Data Catalog will have proposed data classes.
- Either
- Go to the Semantic Flow tab. Click on Definition and note the term associated with the data class is now presented.
- Click on the term. Go to the Semantic Flow tab. Click on Usage and note the metadata object (and others assigned to the same data class) are now presented.
Example
Go to the MANAGE > Data classes in the banner.
Click the line with the US Social Security Number data class.
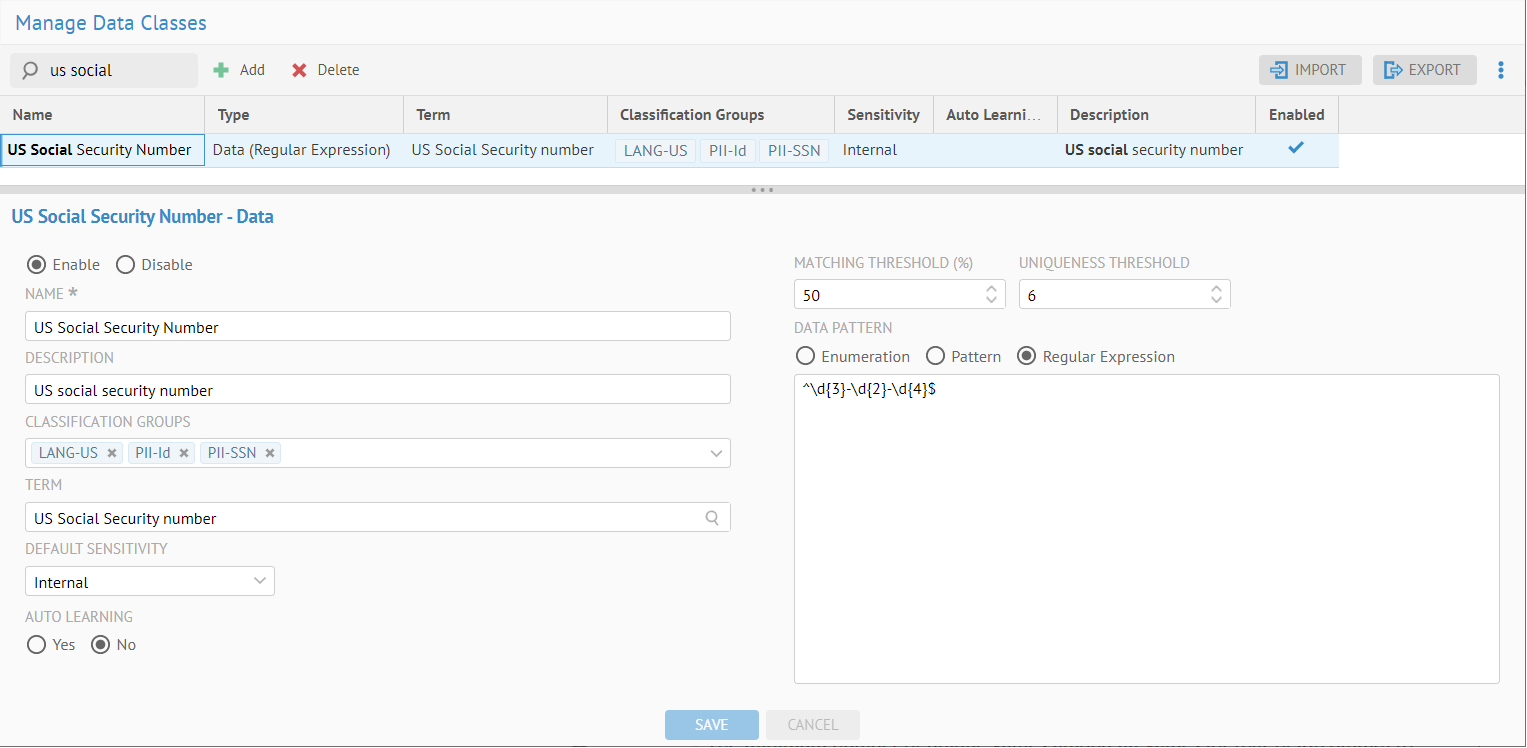
Click the browse icon ( ) next to TERM. Select the term US Social Security Number in the Object Explorer dialog.
) next to TERM. Select the term US Social Security Number in the Object Explorer dialog.

Click OK, then SAVE.
Navigate to the object page of the SSN field in the Employee.csv file.

There are no data classes proposed yet as we have not auto-tagged.
Go to  More Actions > Data Classification
More Actions > Data Classification
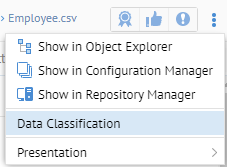
Select PII-SSN for the CLASSIFICATION GROUP.
It is not necessary to selection any data classification group, as leaving it blank would simply use all the data classes defined. However, for performance purposes when you are classifying an entire model or configuration, you may wish to improve performance by specifying a group.
The SSN field is assigned the US Social Security Number data class. Thus, the Name and Business Definition are populated with the information of the SSN term.
Go to the Semantic Flow tab. Click Definition in the upper right.

The US Social Security Number term is provided as one of the definitions.
Click on the term US Social Security Number(first line). Go to the Semantic Flow tab. Click Usage in the upper right.

We see that SSN is classified with this term (because of the auto-tagging).
We can classify the entire data lake at once and see what else is auto-tagged. Navigate to the object page of the Data Lake model and select  More Actions > Data Classification. Again select PII-SSN for the CLASSIFICATION GROUP and click OK.
More Actions > Data Classification. Again select PII-SSN for the CLASSIFICATION GROUP and click OK.
Wait for the operation to finish.
Return to the US Social Security number term and the semantic usage report. Click Diagram on the left.

The ID field is shown as one metadata object (along with others) that use the definition and name of this term.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!