
Auto Learning Data Patterns
The data classification operation uses the data pattern to match data classes to harvested objects with some confidence. You can approve or reject proposed data classes. When you approve or reject a learning data class the application absorbs the information and masters its understanding of the data pattern.
The data classification algorithm handles dictionary and regex data patterns. An example of the dictionary data pattern is [red, blue, green]. The pattern applies to a column when it has a smaller number of distinct values than total sampled rows. A phone number column is an example of a column with regex data patterns. In this case, the majority of sampled rows have unique values that share the same data pattern, like NNN NNN-NNNN.
Just as you may enter a pattern for a data detected data class, the system may learn from what is in the sampling data and suggest patterns based upon what is learned.
Steps
- Ensure that you have created a data-detected data class with the Auto Learning flag set.
- Navigate to the object page of the object (data element) you wish to use as a basis to learn from.
You must have already sampled and profiled the data for that object.
- Assign the data class manually to that object.
- Later, when you have a good set of patterns, you may invoke data classification on other objects to automatically associate the data class with those other objects.
Example
Sign in as Administrator and created a data-detected data class with the Auto Learning flag set as shown:

Search for ProductNumber and pick the one in the Product.csv file. Open its object page and manually assign the Product Number Learned Pattern data class to ProductNumber.
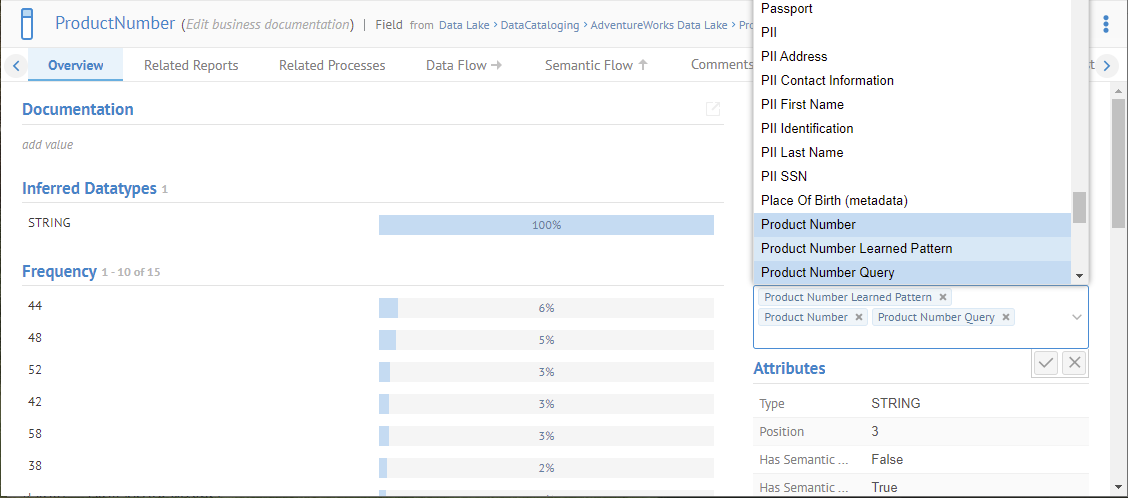
Once the data class is assigned to the object, return to the Product Number Learned Pattern data class in MANAGE > Data Classes and note the patterns are learned:

It picks up all the patterns that fit the THRESHOLDS you specified. We can improve (shorten) this list by adjusting them.
The numbers in blue next to the patterns are the matched weight that particular pattern, with a minimum of 10.
The weight changes according to the following rules:
-Increment weight by one for each matching possible value or pattern when somebody approves a data class for the column.
-Decrement weight by one for each matching possible value or pattern when somebody removes previously approved data class from a column. We also automatically remove the pattern or possible value when the weight turns 0.
-Set weight to 10 for all the current values/patterns when one enables auto learning mode for a data class. This way we treat them as user inputs with the higher weight. It helps to prevent them from being removed from a data class when one rejects the data class from the associated column (see second point above).
Un-check Auto Learning and clear out the DATA PATTERN box of all but one pattern: AA-A999. Click SAVE.
Finally, change the MATCHING THRESHOLD to 10% as this pattern on represented 15% of the data:

and click SAVE.

We have set up the data class, so it is ready to be used for data classification, rather than learning.
Then, go to the object page of the ProductNumber field in the Product.psv file (NOT the Product.csv file we were working with before.
Invoke data classification on that object

The Product Number Learned Pattern data class is now assigned to this field, as well.
Accuracy
With learned data class patterns, as more and more objects suggest a pattern, and accuracy number appears next to the pattern. This allows one to identify which patterns are likely to be more accurate, so one may clean out less accurate patterns.